세미프로젝트 주제를 전세가 예측으로 정하면서 어떤 데이터를 활용할지에 대해 먼저 고민했다.
전세가에 영향을 주는 교육, 교통, 인프라 등이 자연스럽게 떠올랐고 얼마나 근처에 있는지 보다는 주변에 얼마나 많은지에 초점을 두기로 했다.
또한 법정동별, 도로명별 중 전세가의 기준점도 필요했는데 우리 팀은 법정동별 평균 전세가를 예측하기로 하였다.
📌 스타벅스 크롤링
# 스타벅스 크롤링
# 크롬드라이버 실행
driver = webdriver.Chrome()
#크롬 드라이버에 url 주소 넣고 실행
driver.get('https://www.starbucks.co.kr/store/store_map.do?disp=locale')
# 페이지가 완전히 로딩되도록 3초동안 기다림
time.sleep(3)
# 스타벅스 서울 클릭
starbucks_seoul_css = "#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a"
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CSS_SELECTOR,starbucks_seoul_css ))).click()
# 스타벅스 서울 전체 클릭
starbucks_seoul_all_css = "#mCSB_2_container > ul > li:nth-child(1) > a"
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CSS_SELECTOR,starbucks_seoul_all_css ))).click()
time.sleep(3)
#스타벅스 서울 전체 HTML 파싱
html = driver.page_source
soup = BeautifulSoup(html,"html.parser")
container = soup.find("div", id = "mCSB_3_container")
li_all = container.find_all("li")
starbucks_data = []
for li in li_all:
name = li.find("strong").text.strip()
address = li.find("p").text.strip().replace("1522-3232","")
gu = address.split(" ")[1]
each = {"매장이름":name, "주소":address, "구":gu}
starbucks_data.append(each)
df_starbucks = pd.DataFrame(starbucks_data)스타벅스는 주변상권, 유동인구 등을 고려하여 입주하기 떄문에 전세가에 영향을 미칠 것 이라고 판단하에 데이터를 수집하였다.
수집은 스타벅스 홈페이지를 기준으로 서울 전체 매장을 검색하여 600여개의 스타벅스 매장의 주소지를 크롤링하였다.
이 때 HTML을 피싱하기 전 대기시간을 주지 않으면 크롤링이 되지 않으므로 주의!


📌 주소지 변경(카카오 API 활용)
# 카카오 API 이용해 주소 변환(도로명 -> 지번주소)
def road_to_dong(df_name, column):
# 도로명 주소 가져오기
addrs = df_name[column]
# 카카오맵 API로 도로명 주소 가져오기
locations = []
for addr in addrs:
url = 'https://dapi.kakao.com/v2/local/search/address.json?query={}'.format(addr)
headers = {'Authorization': 'KakaoAK ' + '개인API키'}
place = requests.get(url, headers = headers).json()['documents']
locations.append(place)
# 예외 처리하기
total = [] ## 전체 주소
dong = [] ## 동
for i in range(len(locations)):
try:
total.append(locations[i][0].get('address').get('address_name'))
dong.append(locations[i][0].get('address').get('region_3depth_name'))
except IndexError:
print(i,'번째 주소 못가져옴', end ='')
print()
total.append('없음')
dong.append('없음')
except AttributeError:
total.append(locations[i][0].get('road_address').get('address_name'))
dong.append(locations[i][0].get('road_address').get('region_3depth_name'))
# 가져온 데이터 확인하기
total_T = np.array(total).T
dong_T = np.array(dong).T
df_name['지번주소'] = total_T
df_name['동'] = dong_T
return '주소변환완료'법정동을 기준으로 요소들의 갯수를 계산해야 하기에 도로명이나 좌표로 되어있는 데이터들을 수정할 필요가 있었다.
그래서 카카오 API를 활용해서 주소지를 바꾸어 주었고, 좌표도 위의 함수(도로명 주소 변환)와 동일하게 작성하여 수정했다.
이 작업을 하면서 캐글이나 데이콘에 있는 데이터들이 얼마나 깔끔한지 알 수 있었다...
공공데이터들은 작성기준이 없다보니 시군구 없이 주소지가 작성되어 있는 경우, 주소가 바뀌었으나 예전 주소지로 기입이 되어있는 경우 등 API가 인식을 못하는 경우도 있었다.

그럴 경우 이런 식으로 하나하나 검색해보고 채워넣는 수밖에 없었다..
그래서 생각보다 데이터 전처리 과정이 꼼꼼하고 손이 많이 가는 작업이란걸 알 게 해준 시간이었다.
📌 동별 feature 계산
결측치를 처리한 후 동별 공원, 마트, 버스정류장 등 갯수를 계산했다.
# 동별 공원 갯수
df_park_count = df_park['동'].value_counts().to_frame()
df_park_count = df_park_count.reset_index()
df_park_count = df_park_count.rename(columns={'동': '공원', 'index':'동'})
📌 최종 feature
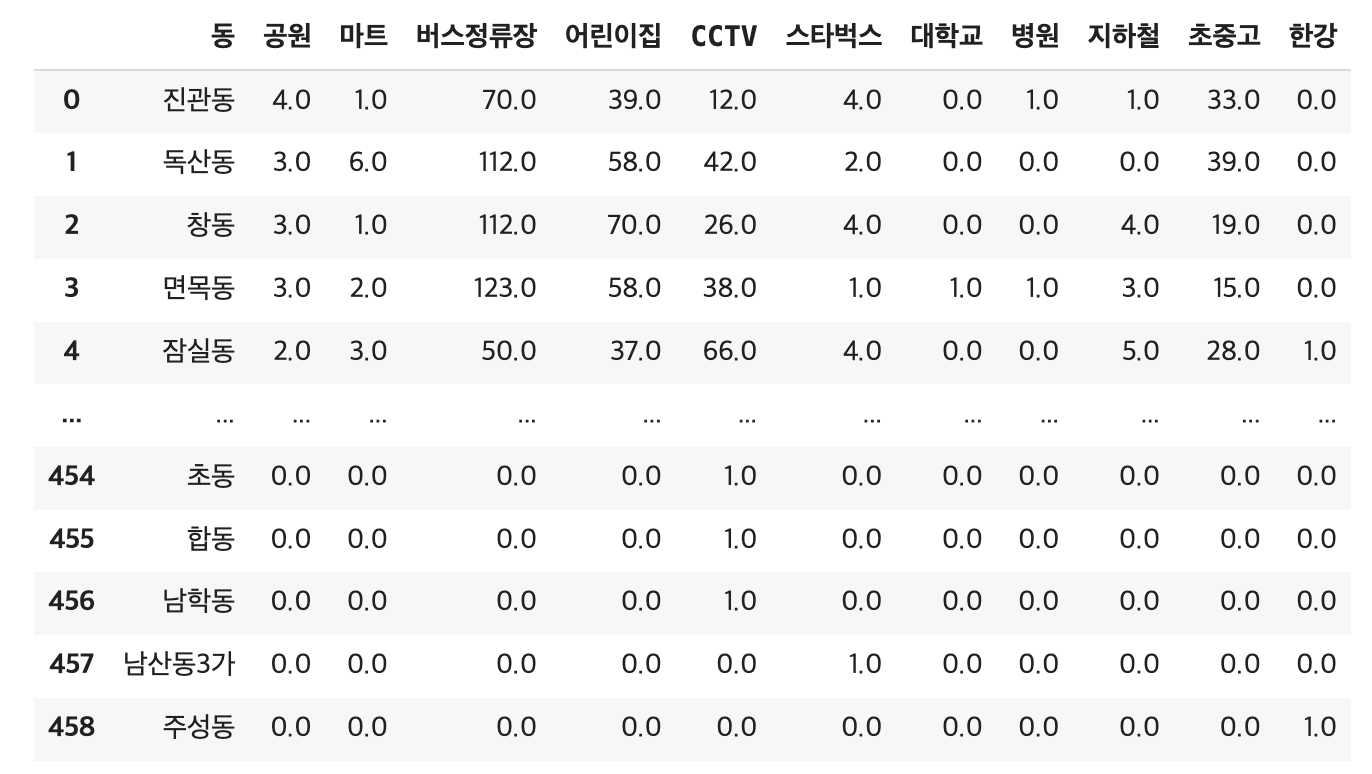
최종적으로 우리가 선정한 종속변수를 동별로 정리할 수 있었다...
데이콘, 캐글 데이터만 다뤄보다 공공데이터로 처음 전처리를 해본 시간이었는데 여러모로 배운게 많았다.
'Project > 전세가 예측' 카테고리의 다른 글
| [Project] 서울 전세가 예측(시각화) (0) | 2024.04.01 |
|---|---|
| [Project] 서울 전세가 예측(모델링) (0) | 2024.03.31 |
| [Project] 서울 전세가 예측(인코딩) (0) | 2024.03.30 |
| [Project] 서울 전세가 예측(데이터 수집 및 전처리)(2) (0) | 2024.03.28 |