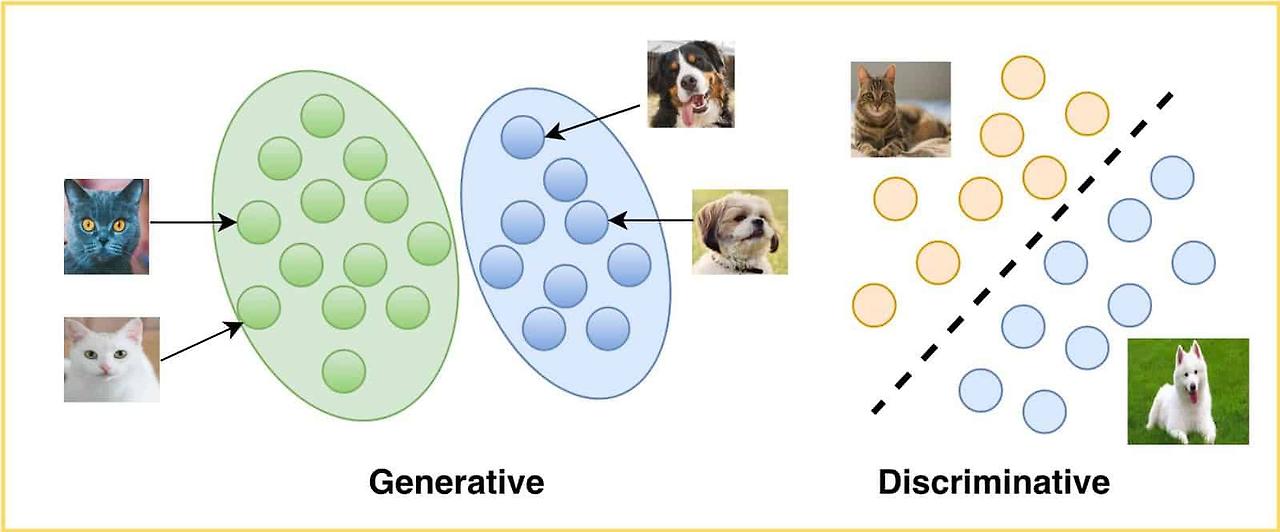
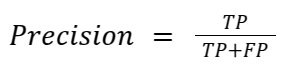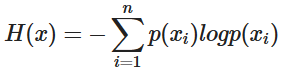AE(Auto Encoder)input 데이터를 latent space로 압축한 후 원본 데이터와 유사하게 reconstruction한 output 데이터 출력Encoder: 입력 데이터를 저차원(latent space)으로 압축Latent Space: 중요한 특징만을 보존한 저차원 표현Decoder: Latent Space에서 원래 입력과 유사한 데이터를 복원 VAE(Variational Auto Encoder)input 데이터를 확률 분포로 변환해 더 일반화된 latent space를 학습하고, 이를 샘플링하여 새로운 데이터 생성 가능KL Divergence를 이용해 정규분포를 따르게 하여 일반화가 잘 되도록 한다.덕분에 새로운 샘플을 뽑더라도 자연스럽고 의미있는 데이터를 추출할 수 있다.