7.1. 언어 모델을 사용한 문장 생성
그림 7-1과 같이 LSTM 계층을 이용한 언어 모델이 'you say goodbye and I say hello' 라는 말뭉치를 학습했다고 가정해보자.
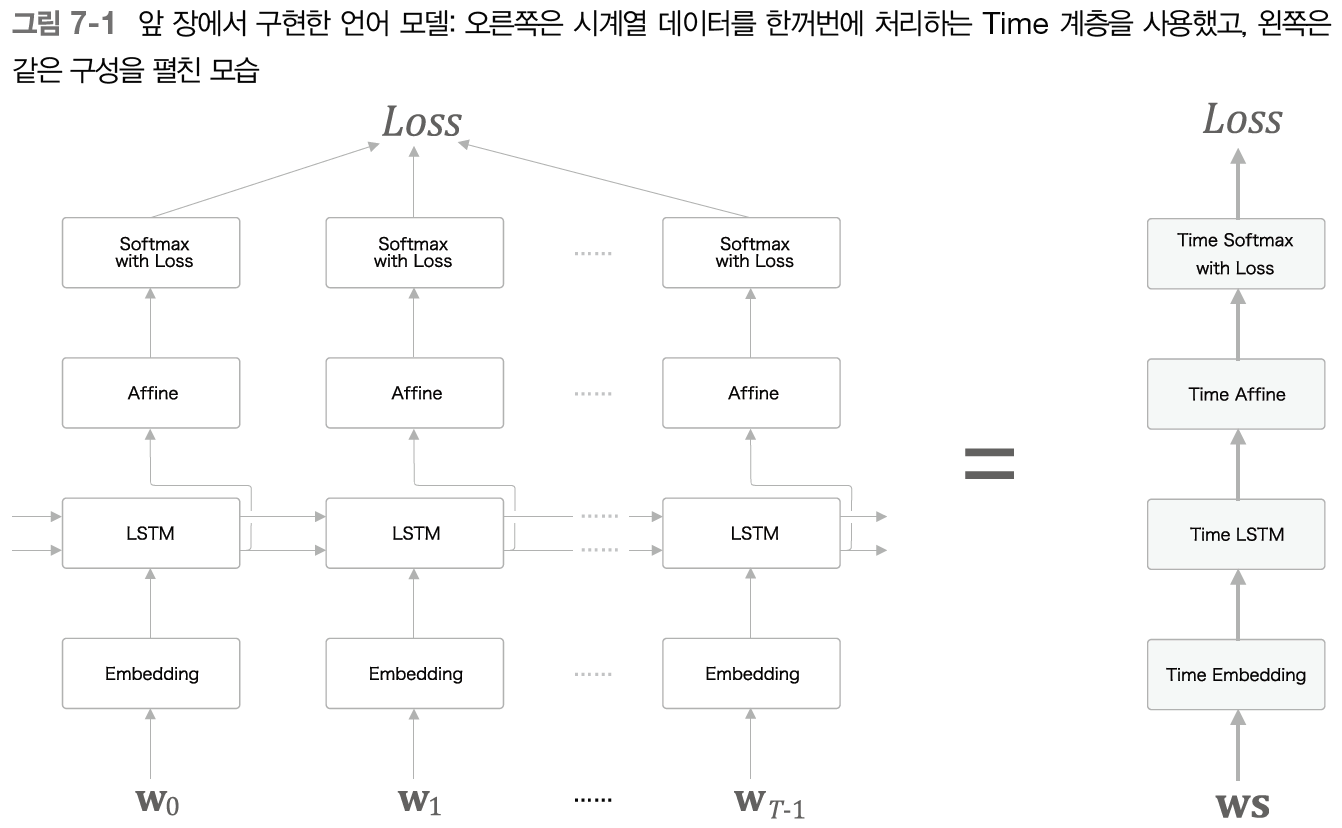
그림 7-2처럼 'I'라는 단어를 주었을 때 다음 단어를 새로 생성하려면 어떻게 해야 할까?
1. 확률이 가장 높은 단어를 선택하는 방법(결과가 일정한 '결정적'인 방법)
2. 후보단어의 확률에 맞게 선택하는 방법,
즉 확률이 높은 단어는 선택되기 쉽고 확률이 낮은 단어는 선택되기 어렵다.(결과가 매번 다른 '확률적'인 방법)

확률적으로 'say'라는 단어가 선택된 후 그림 7-4처럼 두 번째 단어를 샘플링한다.

이와 같은 작업을 원하는 만큼 반복한다.(or <eos>같은 종결 기호가 나타날 때까지 반복한다.)
문장 생성 구현은 https://github.com/ExcelsiorCJH/DLFromScratch2.git 참고
7.2. seq2seq
seq2seq(sequence to sequence) : 2개의 RNN을 이용하는 시계열 데이터를 다른 시계열 데이터로 변환하는 모델
✔️ seq2seq의 원리
seq2seq는 Encoder-Decoder 모델이라고도 한다.
인코딩(부호화) : 정보를 규칙에 따라 변환하는 것 (예. 'A'라는 문자를 '100001'이라는 이진수로 변환하는 일)
디코딩(복호화) : 인코딩된 정보를 원래의 정보로 되돌리는 것 (예. '100001'이라는 이진수를 'A'라는 문자로 변환하는 일)

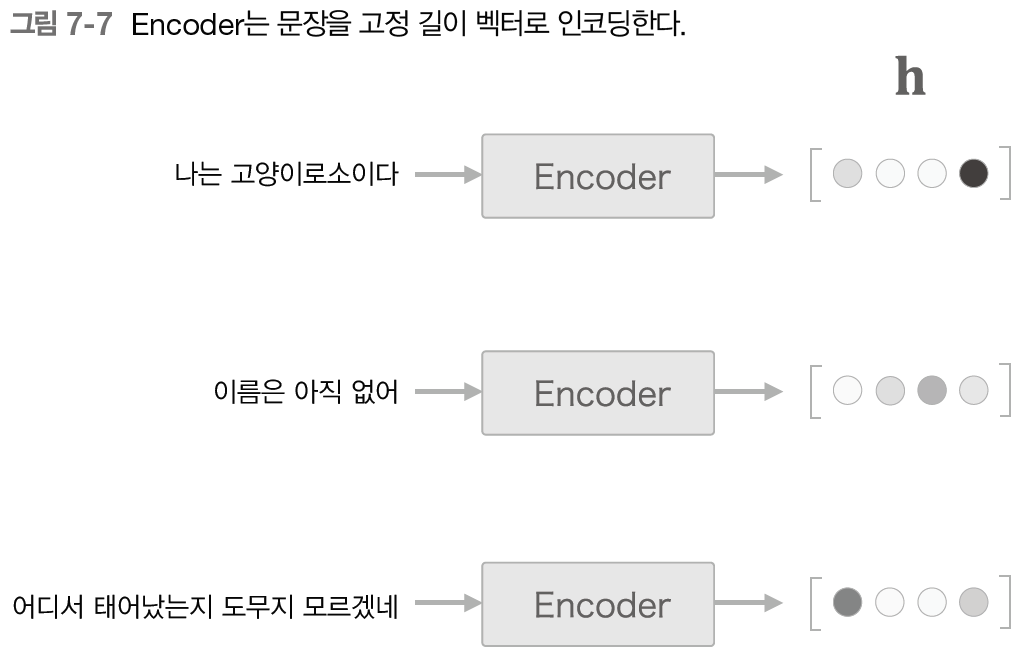
Encoder는 RNN을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환한다.
그림 7-6은 LSTM을 사용하였지만 단순한 RNN이나 GRU 등도 가능하다.
h는 LSTM 계층의 마지막 은닉 상태이다. 즉 이 마지막 은닉 상태 h에 입력 문장(출발어)를 번역하는데 필요한 정보가 인코딩된다.
그림 7-7과 같이 LSTM의 은닉 상태 h는 고정 길이 벡터이기 때문에 인코딩한다는 것은 결국 임의 길이의 문장을 고정 길이 벡터로 변환하는 작업이다.

Decoder는 언어 생성 모델과 동일하다.

이러한 Encoder와 Decoder를 연결하면 그림 7-9와 같다.

✔️ 가변 길이 시계열 데이터
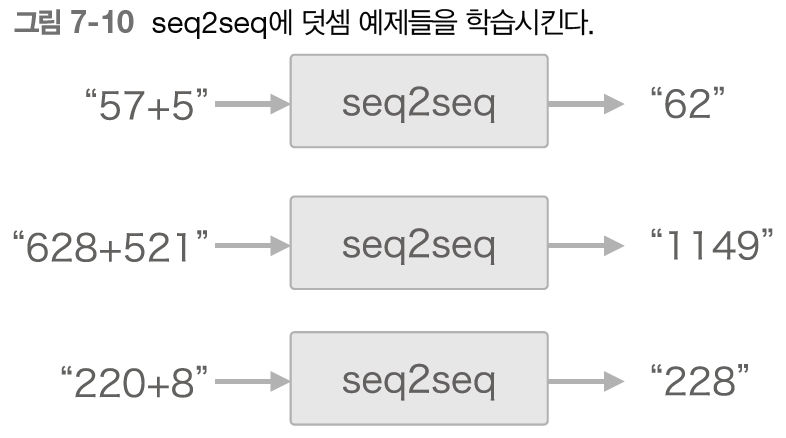
seq2seq가 덧셈 문제를 푼다면, 덧셈의 '예(샘플)'로부터 사용되는 문자의 패턴을 학습한다.
이때, word2vec이나 언어모델은 문장을 '단어'단위로 분할하지만, '덧셈'은 '문자'단위로 분할하여야 한다.
'덧셈'을 문자(숫자)의 리스트로써 다루면 덧셈 문장 '57+5', '628+521'이나 대답 '62', '1149'의 문자 수가 문제마다 다르다.
'57+5'는 4문자, '628+521'는 7문자로, 샘플마다 데이터의 시간 방향 크기가 다르다.
즉 '가변 길이 시계열 데이터'를 다룬다.
이를 해결하기 위해서는 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 패딩을 사용한다.

7.3. seq2seq 구현
✔️ Encoder 클래스

그림 7-14처럼 Encoder에서 LSTM계층의 은닉상태 h를 출력하고 이 은닉상태 h가 Decoder로 전달된다.
여기서 시간 방향을 한꺼번에 처리하는 Time 계층을 이용하면 그림 7-15처럼 된다.

class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params # 리스트
self.grads = self.embed.grads + self.lstm.grads # 리스트
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :] # 마지막 hidden state
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
✔️ Decoder 클래스

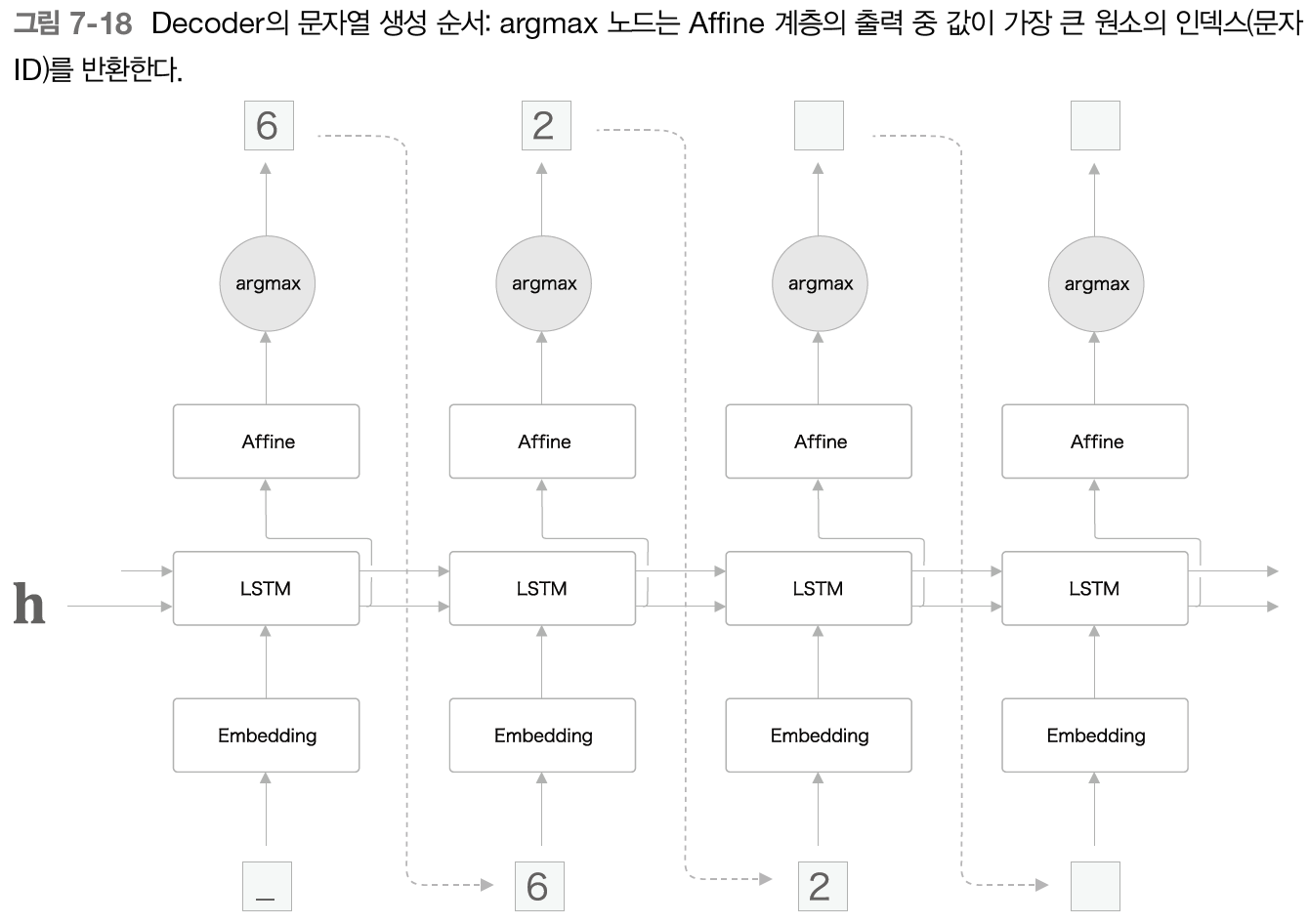
'덧셈'문제는 '확률적'인 답보다는 '결정적'인 답이 적절하기 때문에 그에 맞춰 생성모델도 구현해보자.
그림 7-18과 같이 softmax 계층 대신 'argmax' 노드를 통해 Affine 계층이 출력하는 점수가 가장 큰 원소를 선택한다.
따라서 학습할 때는 softmax, 생성할 때는 argmax를 사용한다.
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
✔️ seq2seq 클래스
마지막으로 seq2seq 클래스는 Encoder 클래스와 Decoder 클래스를 연결하고 Time Softmax with Loss 계층을 이용해 손실을 계산한다.
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
7.4. seq2seq 개선
✔️ 입력 데이터 반전(Reverse)
입력 데이터의 순서를 반전시키면 학습 진행이 빨라져서 최종 정확도도 좋아진다는 문헌이 있다.

✔️ 엿보기(Peeky)
벡터 h에는 Decoder에게 필요한 정보가 모두 담겨 있다.
하지만 개선 전에는 최초 시각의 LSTM 계층만이 벡터 h를 이용하고 있다.
그래서 개선 후에는 h를 Decoder의 다른 계층에게도 전해준다.
그림 7-26과 같이 모든 시각의 Affine 계층과 LSTM 계층에 h를 전해준다.(집단지성)

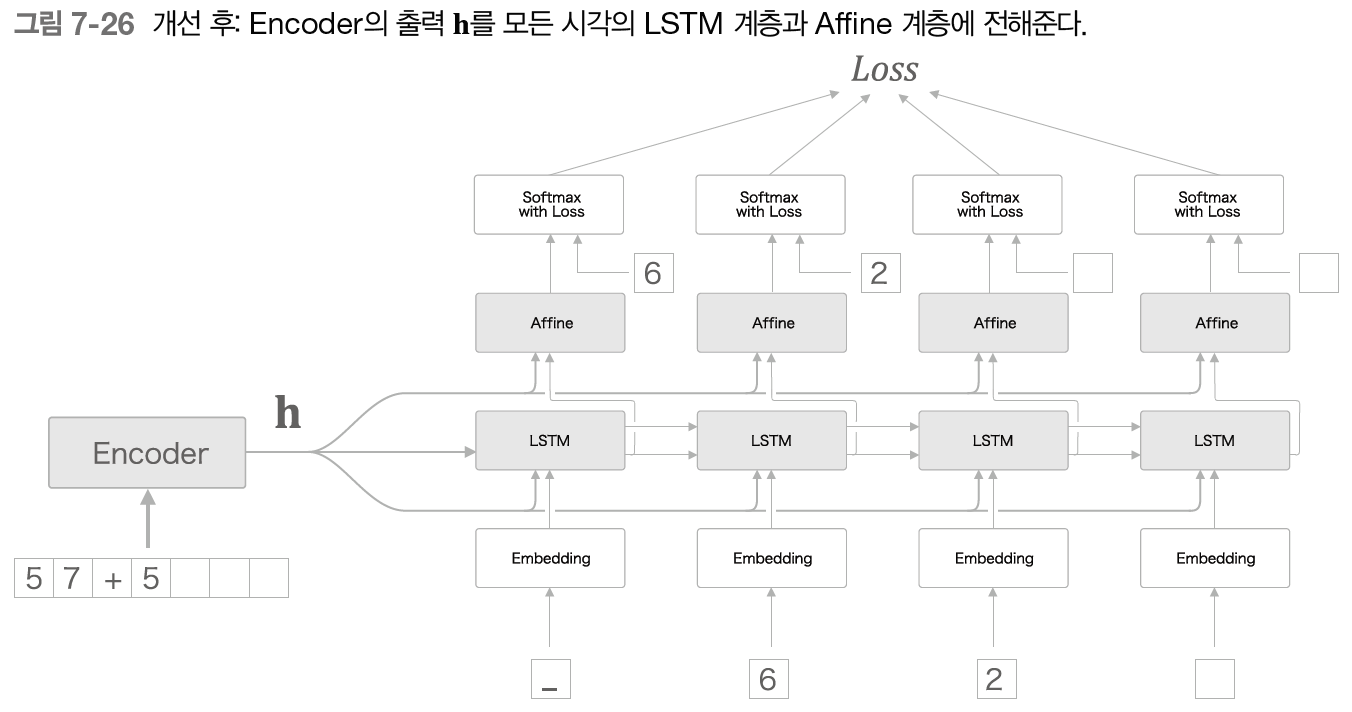
LSTM 계층과 Affine 계층에 입력되는 벡터가 2개씩이 되었는데, 이는 실제로 두 벡터가 연결(concatenate)된 것을 의미한다.
따라서 그림 7-27과 같이 concat 노드를 이용해 계산 그래프를 그려야 정확하다.

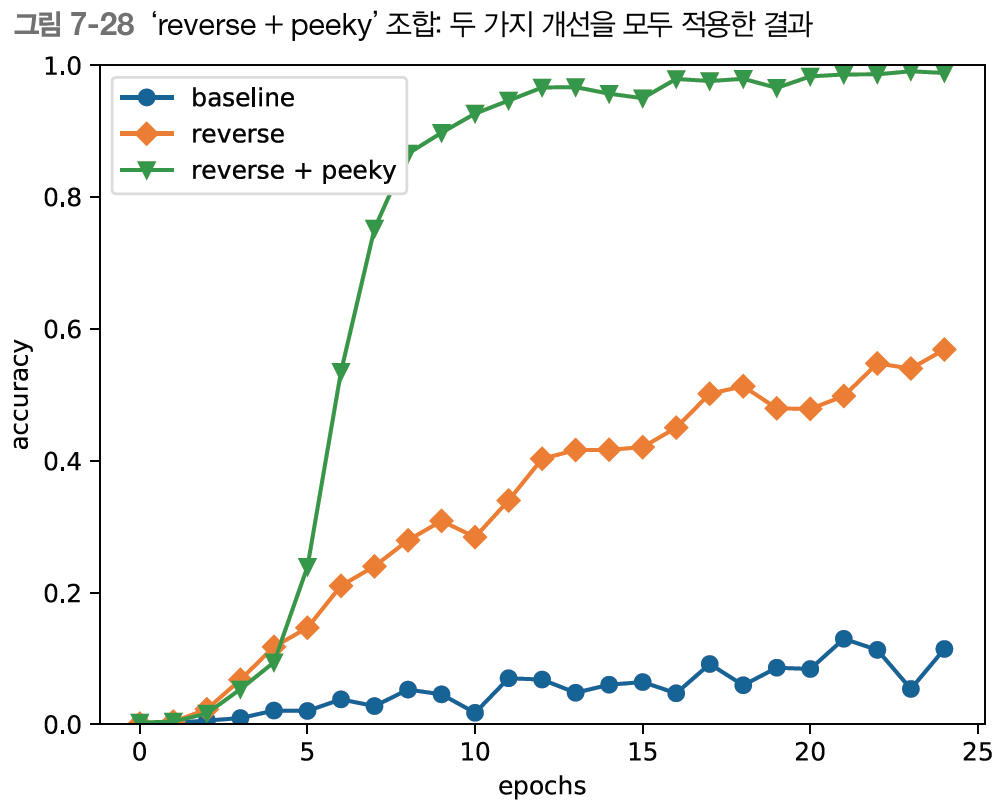
Reverse와 Peeky을 적용한 결과는 그림 7-28과 같다.
7.6. 정리
- RNN을 이용한 언어 모델은 새로운 문장을 생성할 수 있다.
- 문장을 생성할 때는 하나의 단어(혹은 문자)를 주고 모델의 출력(확률분포)에서 샘플링하는 과정을 반복한다.
- RNN을 2개 조합함으로써 시계열 데이터를 다른 시계열 데이터로 변환할 수 있다.
- seq2seq는 Encoder가 출발어 입력문을 인코딩하고, 인코딩된 정보를 Decoder가 받아 디코딩하여 도착어 출력문을 얻는다.
- 입력문을 반전시키는 기법(Reverse), 또는 인코딩된 정보를 Decoder의 여러 계층에 전달하는 기법(Peeky)은 seq2seq의 정확도 향상에 효과적이다.
- 기계 번역, 챗봇, 이미지 캡셔닝 등 seq2seq는 다양한 애플리케이션에 이용할 수 있다.
'Deep Learning' 카테고리의 다른 글
| Entropy, Cross entropy loss란? (0) | 2024.04.28 |
|---|---|
| [밑바닥부터시작하는딥러닝2] Chapter 8. 어텐션 (0) | 2024.04.23 |
| [밑바닥부터시작하는딥러닝2] Chapter 6. 게이트가 추가된 RNN (0) | 2024.04.21 |
| [밑바닥부터시작하는딥러닝2] Chapter 5. 순환 신경망(RNN) (0) | 2024.04.20 |
| [밑바닥부터시작하는딥러닝2] Chapter 4. word2vec 속도 개선 (0) | 2024.04.19 |