Learning Transferable Visual Models From Natural Language Supervision
https://arxiv.org/abs/2103.00020
총 48페이지의 방대한 논문으로 다 읽지는 못했다. 하지만 신인의 패기(?)로 첫 세미나를 해당 논문으로 진행했었는데 그 때의 발표자료를 참고하여 리뷰를 작성해보려 한다.
1. Introduction
NLP에서 GPT와 같이 raw text를 이용하여 학습하는 Pre-training 방법이 몇 년간 발전해왔다. 그러나 computer vision에서는 여전히 label 데이터셋을 사용하고 있어 저자들은 web text로부터 pre-training을 하는 방법이 computer vision에 돌파구가 될 것이라 생각했다. 이를 바탕으로 CLIP이 탄생했다.
Background
CLIP은 아래의 3가지 문제점을 해결한다.
- 보통은 pre-training 이후 특정 데이터셋에 fine-tuning을 해야 모델 활용이 가능하다. 이로 인해 다른 분야에 대해서 활용이 불가하여 일반화가 되지 않는다. 저자들은 이를 해결하기 위해 fine-tuning 없는 zero-shot prediction을 제안한다.
- dataset을 위해 labeling 과정을 거쳐야 하는데 이는 많은 시간과 비용이 소요된다. 이러한 비용이 들지 않도록 저자들은 인터넷에서 raw text를 활용하였다.
- ImageNet같은 데이터셋으로 학습 후 실제 환경에 적용했을 때 손그림, 약간의 변형 등을 주었을 때 제대로 적용되지 않는다는 문제가 있으나 실험결과 CLIP은 해결이 된 것을 확인할 수 있다.
2. Contribution
- Natural Language Supervision
자연어 supervision은 단지 representation을 학습하는 것이 아니라 language representation과의 연결을 학습함으로써 유연하게 zero-shot transfer가 가능하다.
- Creating a Sufficiently Large Dataset
MS-COCO, Visual Genome, YFCC100M과 같은 데이터셋이 많이 활용되었는데 natural language supervision의 많은 데이터를 활용할 수 있는 장점을 살릴 수 없어 인터넷에서 수집한 4억개의 이미지, 텍스트 쌍의 데이터셋을 구축하였다.
- Selecting an Efficient Pre-Training Method
저자들은 natural language supervision을 스케일링하기 위해서 핵심은 학습효율성임을 확인했다. 아래의 파란색 그래프 VirTex 방법을 이용했으나 일반적인 Bag of Words Prediction과 3배차이가 날 정도로 효율이 훨씬 좋지 않았다. predictive보다는 contrastive가 좀 더 효율이 좋다는 논문을 참고하여 앞선 두가지 방법은 단어의 정확한 의미에 초점을 맞췄으나 저자들은 텍스트와 이미지간의 연관성을 고려한 CLIP 방안을 생각하게 되었다. 그 결과 효율이 4배 더 향상됨을 확인할 수 있다.

3. Method
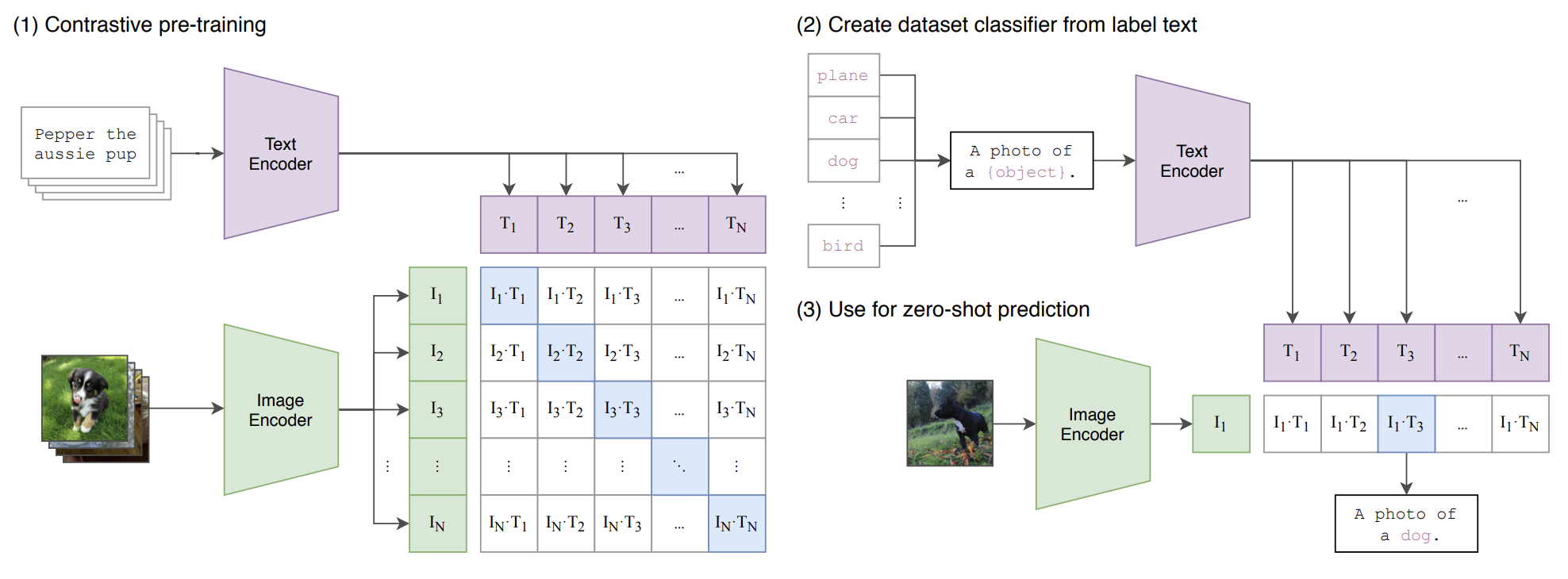

N개의 배치를 가진 이미지, 텍스트 pair를 Text encoder와 image 통해 벡터화를 시킨다. 이 두 개를 내적하여 cosine 유사도를 구한 후 구한 cosine 유사도를 실제 pair 끼리는 유사도가 높게, 아닌 pair는 유사도가 낮도록 학습시킨다. 이 때 cross entropy loss를 활용한다.
Figure 3의 pseudocode를 보면 image, text 배치를 각각의 encode로 보내고 linear layer를 통해 embeding space로 보내게 된다. 그 다음 내적을 통해 각각의 positive pair와 negative pair가 학습되도록 cross entropy loss를 활용하는 것을 볼 수 있다. 즉 image encoder에 이미지를 넣고 라벨들을 text encoder에 넣어서 dot product 후 가장 cosine similarity가 높은 라벨을 채택하는 방식이다.
이 때 image encoder는 ResNet과 ViT를 사용하며, text encoder는 transformer 사용한다.
inference 할 때는 다른 training 없이 데이터셋의 이미지 하나를 이미지 인코더에 보내고 N개 클래스에 해당하는 텍스트를 인코더에 보내 내적을 하여 cosine 유사도가 가장 높은 클래스를 채택하는 방식으로 fine-tuning없이 바로 적용할 수 있어 이를 zero-shot prediction이라고 정의한다.
하지만 여기서 문제점이 발생하는데 첫번째로 동음이의어 문제이다. label만이 제공될 경우 image를 설명하는 context로 학습하는 CLIP은 동음이의어 구분이 힘들다.(이에 대해서 논문에서는 따로 해결방안을 언급하지 않은 듯하다. 다만 이미지와 텍스트를 연결하여 가까운 벡터로 만들기 때문에 간접적으로 해결이 되며 문장 형태의 prompt로 보완이 되서 3.1.4 PROMPT ENGINEERING AND ENSEMBLING에 넣은 건 아닐까 싶다.) 그 다음은 textencoder에 singleword로 입력했는데, 보통 인터넷에 글을 작성할 때 단어가 아닌 문장형식으로 작성한다. 따라서 singleword를 prompt를 사용해 문장형식으로 만들어주었다. 데이터셋의 label에 A photo of a {label}로만 수정해서 text encoder에 넣어도 정확도가 1.3% 향상하며(prompt engineering), A photo of a big {label} / small {label} 앙상블을 통해 3.5~5% 상승하는 것을 확인할 수 있다.

4. Experiments
INITIAL COMPARISON TO VISUAL N-GRAMS
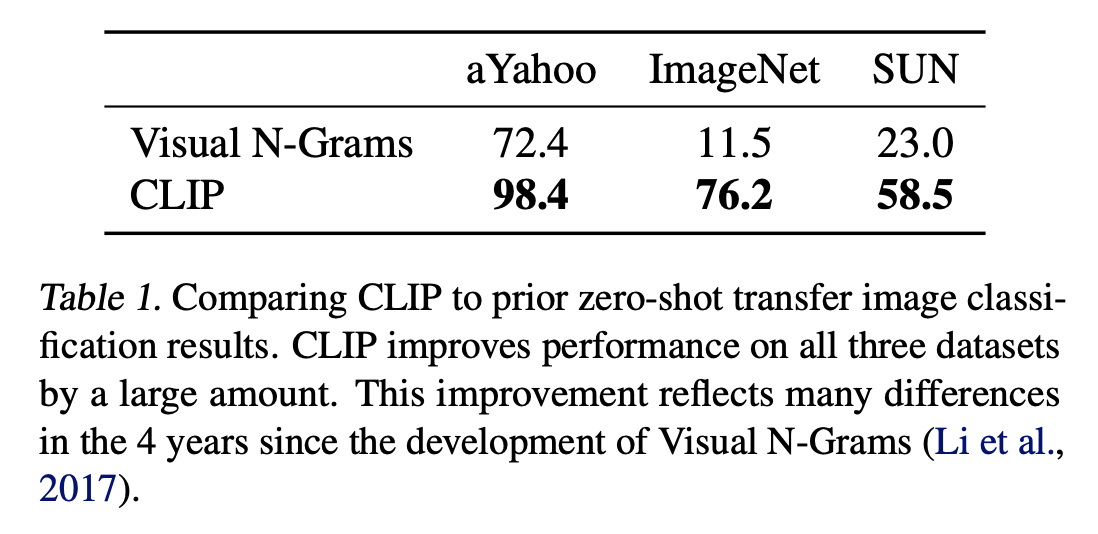
당시 4년전 발표된 Visual N-Grams가 유일한 zero shot transfer방식이었기 때문에 상당히 향상된 성능을 확인할 수 있다.
ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE
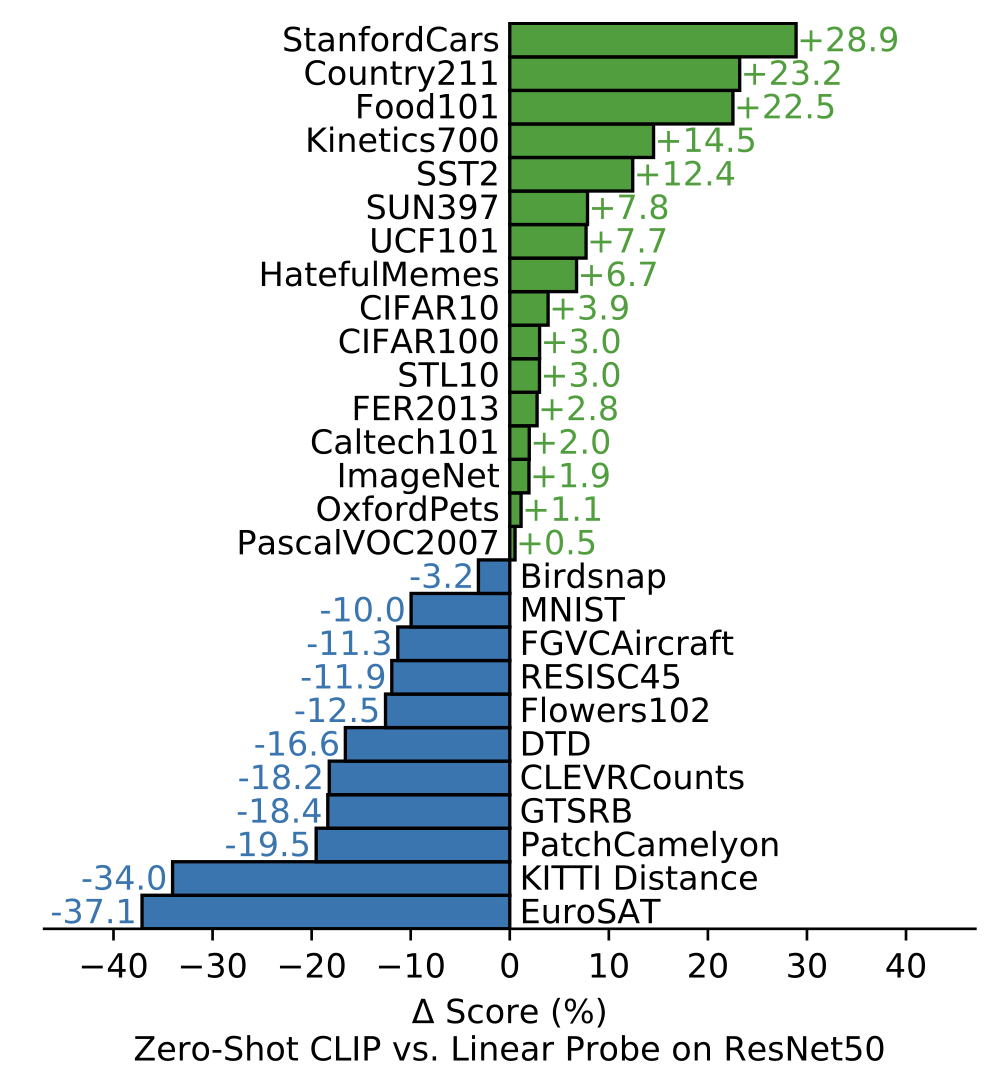
Figure 5를 보면 Linear probe방식과 zero-shot방식을 데이터셋 27개로 비교했을 때, 16개가 기존보다 더 성능이 좋아졌다. StanfordCars, Food101 / Flowers102, FGVCAircraft와 같은 특정 데이터셋에서는 극과 극의 성능을 보이는데 학습데이터의 편향이 원인인 것으로 보인다. Kinetics700과 같은 비디오와 관련된 데이터셋에서도 좋은 성능을 보이며, 이는 CLIP이 명사보다는 동사로 supervision하기 때문으로 보인다.
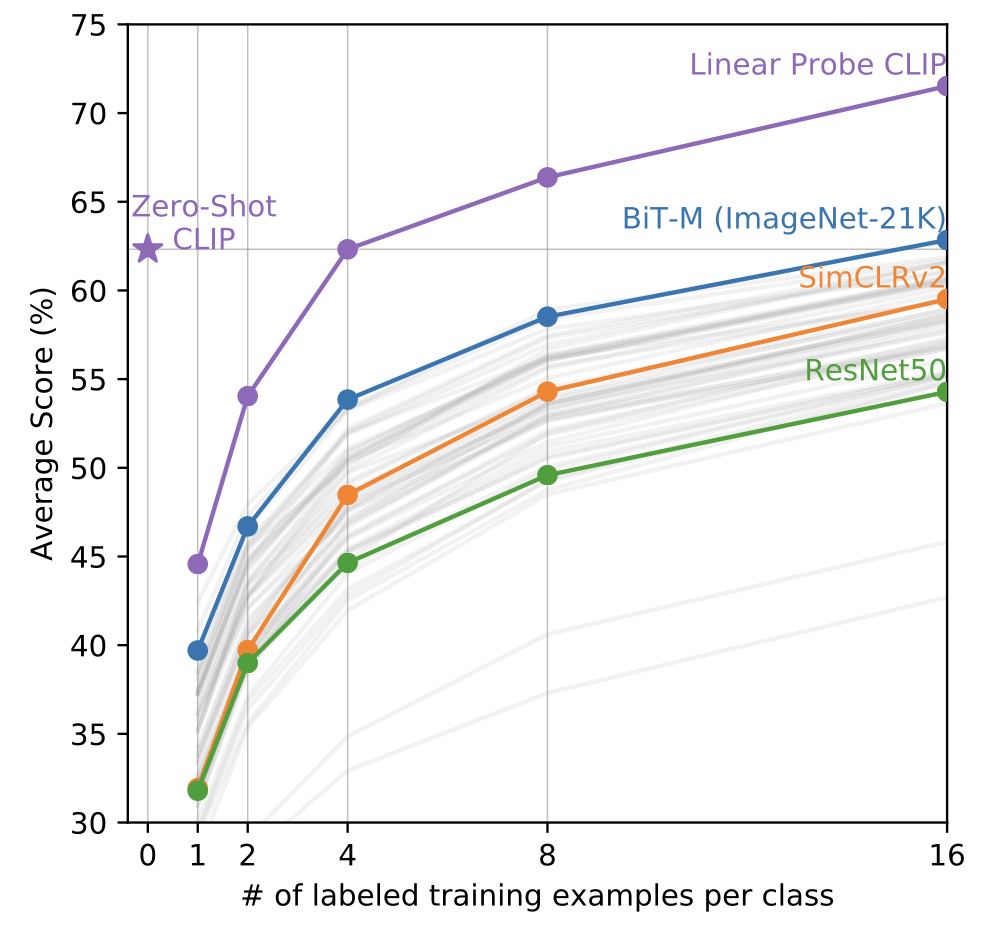
Figure 6을 보면 CLIP이 supervised 모델들보다 좋은 성능을 보인다는 것을 알 수 있다. 이 때 Linear Probe CLIP이란 CLIP의 마지막에 Linear classifier를 추가한 개념이다. 당연하게도 example이 늘어날수록 성능개선이 되는 것도 볼 수 있다.
특이한 점이 저자들은 zero-shot이 one-shot보다 성능이 안 좋을 것으로 예상했지만 오히려 더 좋다는 것이다. 새로운 layer를 모델에 추가해 학습하면서 클래스 당 1, 2장으로는 충분한 학습이 되지 못하여 성능이 더 나빠지며, one-shot이 더 성능이 안 좋은 것은 context-less 데이터의 경우 one-shot 안에 수많은 가설이 존재할 수 있기 때문이다.
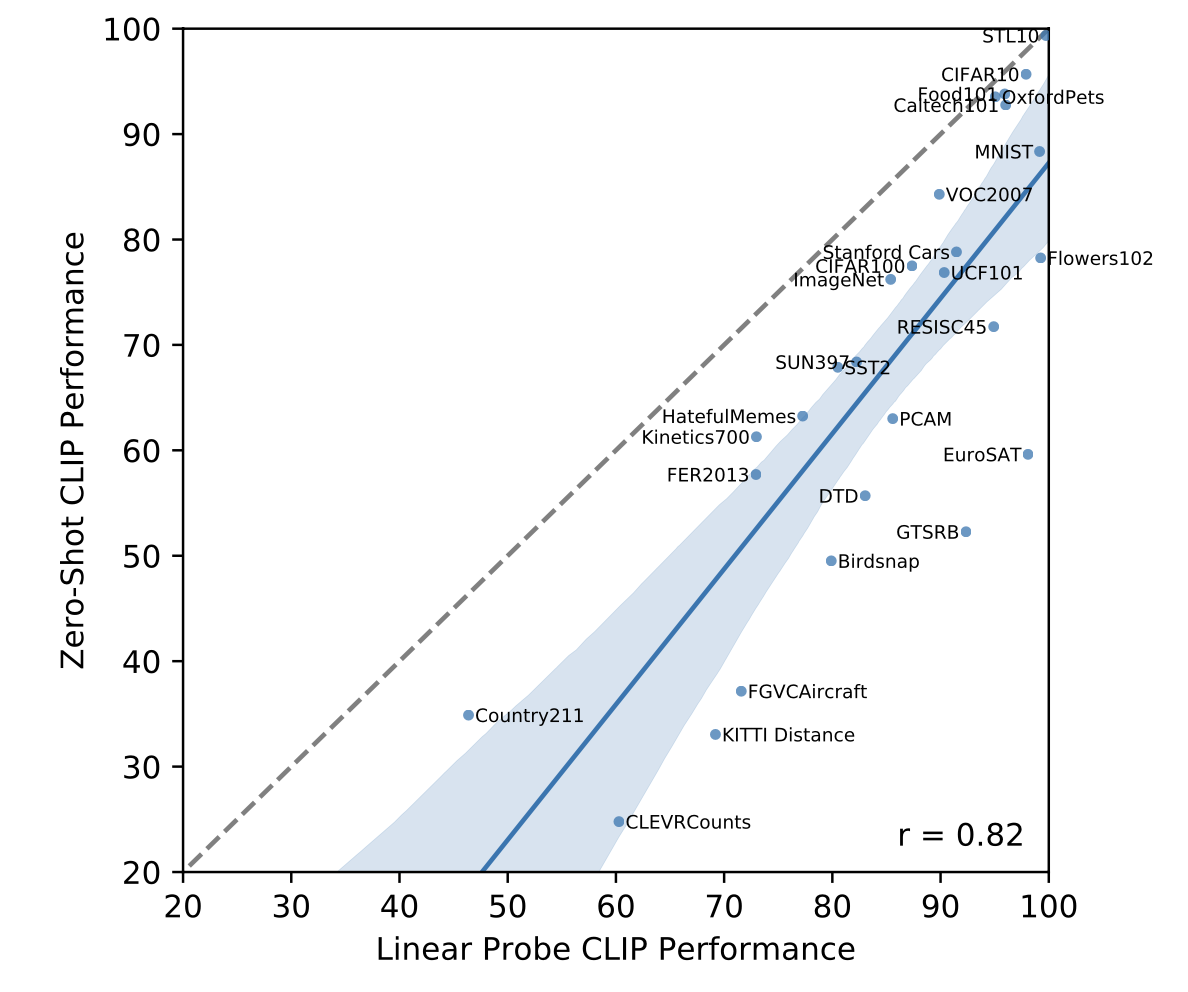
그렇다고 zero-shot이 fully-supervised classifier의 성능을 따라가진 못한다.
Robustness to Natural Distribution Shift
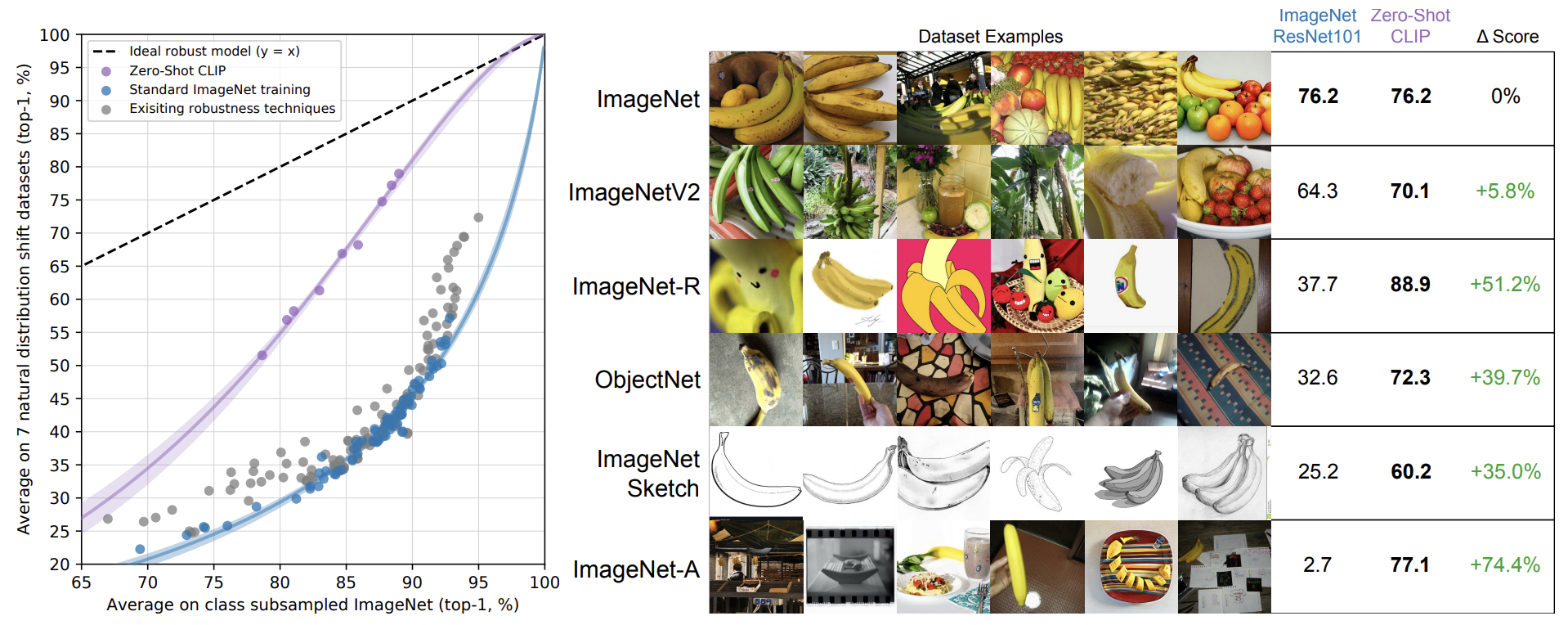
CLIP으로 학습했을 때 ResNet으로 학습한 것에 비해 Robustness하다. ImageNet 외에 나머지 데이터셋은 ImageNet에 natural distribution shift를 한 것이다. 바나나의 형태를 스케치하거나 조금씩 변화한 이미지로 테스트했을 때 CLIP은 정확도를 유사하게 유지하는 반면 ResNet은 정확도를 유지하지 못하는 것을 확인할 수 있다.
Comparison to Human Performance
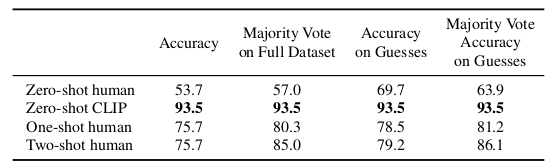
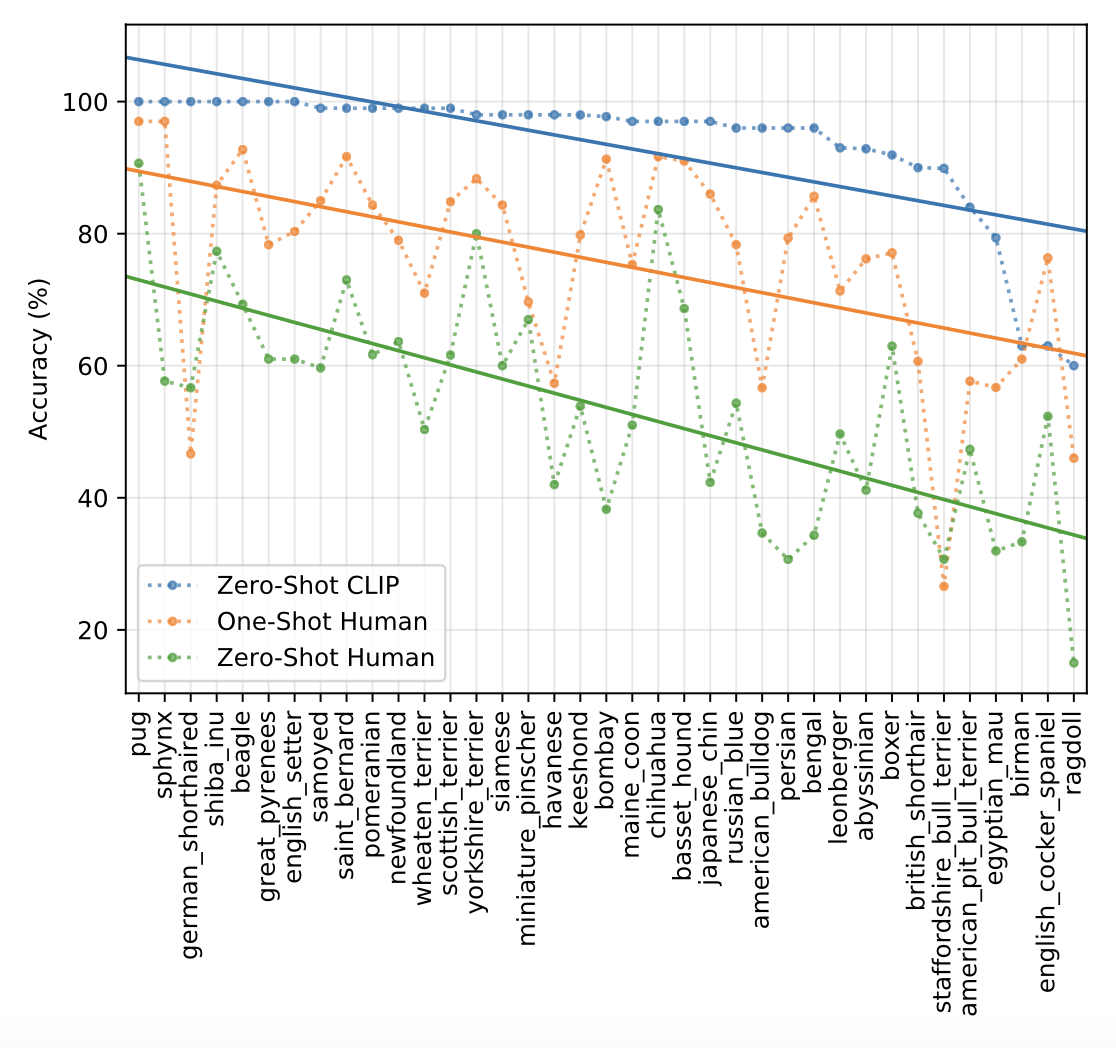
인간과 CLIP의 zero-shot 성능을 비교하고 인간의 one-shot, two-shot을 비교하기 위해 강아지, 고양이 품종을 선택하는 Oxford Pets 데이터세트로 실험을 진행하였다. 인간은 zero-shot보다 one-shot 때 성능이 크게 향상된 것을 볼 수 있는데, 이는 인간이 알고 모름을 정확히 인지한다는 것을 의미한다. (이 결과를 보면서 zero-shot을 human과 비교했을 때 좋은 정확도를 보여주고 있는데 이것이 감히 zero-shot이라고 할 수 있는가에 대한 의문이 들었다. 데이터셋의 raw text 안에 강아지, 고양이 품종을 예측할만한 학습데이터가 있었다면 이것이 zero-shot인가? 인간의 zero-shot과는 다른 기준이지 않나? 라는 생각이 들었으나 CLIP이 사전학습을 하듯 인간도 생활을 하면서 사전학습을 한다고 할 수 있을 듯 하다.)
5. Conclusion
CLIP은 자연어를 통해 많은 dataset을 zero shot transfer가 가능하게 하였으며, 좋은 성능을 보인다.
6. Limitation
1. 특정 분야의 데이터셋에 성능이 좋지 않다. (자동차 모델, 꽃 종류, 항공기 변형 등 편향된 데이터)
2. 개체수 계산과 같은 추상적이고 체계적인 작업은 어렵다.
3. out-of-distribution 같은 데이터에는 취약하다. 예를 들어 MNIST 같은 손글씨, raw pixel같은 데이터에 취약한대, 그 이유로 학습데이터에 이와 유사한 데이터가 없는 것을 확인할 수 있었다. 다른 의미에서 CLIP을 통해 일반화가 해결되진 못했다.
4. CLIP은 인터넷의 이미지와 쌍을 이루는 데이터셋으로 학습하기 때문에 필터링되지 않고 선별되지 않아 사회적 편견(social bias)를 학습한다. 이는 사회적 이슈가 될 수 있다. (chat GPT도 유사한 문제가 있었던 것으로 기억하는데 chat GPT는 이를 어떻게 해결했을까?)
저자들은 위와 같은 limitation이 CLIP의 zero-shot 능력을 더 향상시킬 수 있는 찬스라고 표현하였다.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] PDF: A Probability-Driven Framework for Open World 3D Point Cloud Semantic Segmentation (0) | 2024.12.05 |
|---|---|
| [논문 리뷰] Entropic Open-set Active Learning (1) | 2024.12.04 |
| [논문 리뷰] Open-world Semantic Segmentation for LIDAR Point Clouds (0) | 2024.11.26 |
| [논문 리뷰] Open-World Semantic Segmentation Including Class Similarity (0) | 2024.11.25 |
| [논문 리뷰] Feedback-Guided Autonomous Driving (1) | 2024.11.24 |