Open-Vocabulary 3D Semantic Segmentation with Foundation Models
0. Abstract
3D 환경에서 카테고리의 제한없이 다양한 범위의 물체를 인식하는 것은 real-world에서 불가피해졌다. 이를 위해 open vocabulary 3D semantic segmentation framework인 OV3D를 소개한다. OV3D는 vision과 language foundation model을 활용하여 3D point cloud와 문맥적인 entity description간을 일치시켜 광범위한 open world 지식을 활용한다. entity description은 문맥적인 정보를 활용하여 더 상세하고 정확한 이해를 할 수 있게 해준다. 이처럼 3D domain에서도 3D point feature들과 entity text feature를 일치시켜, open vocabulary recognition에서 활용한다.
1. Introduction

기존의 open vocabulary recognition은 visual과 language feature를 같은 feature space에 통합하여 일반화된 lanugage model을 활용하는 것이었다. 이는 보통 2D open vocabulary framework에서 활용되었다. 이를 위해 image와 text data 쌍이 필수적이다. 그러나 image, text는 Internet에 활용가능한 자료가 많지만 point cloud와 text는 이용에 제한이 많다. 현재 point cloud와 text를 연결하기 위해 접근성이 좋은 image를 매개체로 많이 사용한다. 일반적으로 point cloud와 image feature를 맞추는 방법을 사용한다. 또다른 방법으로, multi view image로 나타낸 3D를 이용하여 caption을 만들어내는 방법도 있다. 하지만 이러한 방법으로 세밀하게 point to text correspondence하는 것은 어려울 수 있다.
이를 위해 open vocabulary 3D semantic segmentation인 OV3D를 제안한다. OV3D도 기존 방법들과 같이 3D point cloud와 text description을 연결하지만 vision, language foundation model을 이용해 open world concept를 활용하는데 중점을 둔다. 본 연구의 주요 성과는 1) Fine-grained correspondence 2) Context-enriched Point-Text Alignment이다.
구체적으로 크게 3가지요소로 구성된다.
1) Mapping Image to EntityText: 전체 image를 captioning하는 것 대신에 EntityText같은 entity level text description을 생성하는 Large Vision Language Model(LVLM)을 활용한다.
2) Associating Pixel with Entity Text: image와 EntityText를 더 fine-grained한 연결을 하기 위해, Segment Anything과 같은 vision foundation model을 활용해 class에 영향을 받지 않는 segment를 만들어낸다. 그 후 공용 vision-language feature space를 만들어 낼 수 있는 vision-language model을 활용하여 EntityText와 segment를 연결시킨다. 이를 통해 fine-grained pixel-EntityText correspondence를 얻을 수 있다.
3) Connecting Point and EntityText via Pixel: 3D point를 multi view image로 투영시켜 2D pixel position을 얻어낸다. pixel-EntityText correspondence를 기반으로 entity information을 각 point에 활용하여 fine-grained (point, EntityText) pair를 만들 수 있다.
이를 통해 3D point와 entitytext feature간의 fine-grained한 일치를 하게 되었고, open vocabulary semantic segmentation에서 최신 성능을 달성했다.
3가지 contribution은 다음과 같다.
1. vision과 language foundation을 활용해 3D open vocabulary recognition을 할 수 있는 framework를 제안한다.
2. text와 point간의 더 섬세한 correspondence를 가능하게 하는 fine grained point-to-EntityText 일치를 소개한다.
3. open-world recognition에서 좋은 성능을 보이며, 다양한 데이터셋에서 활용가능한 superior zero-shot semantic segmentation이 가능하다.
2. Related Work
Foundation Model
vision-lanugage model과 segmentation vision model은 robust하고 우수한 zero-shot 성능을 보여준다.
2D Open-Vocabulary Learning
기존의 vision-language foundation 모델들(CLIP, ALIGM 등)이 image-level recognition에 집중되어있었다면, 최근 연구에는 object-level이나 pixel-level로 집중되고 있다.
3D Open-Vocabulary Learning
3D는 2D보다도 데이터가 부족하기 때문에 challenge하다. zero-shot 에서 3D data와 text description간의 연결이 부족하기 때문에, 최근 3D point cloud를 multi-view 2D image로 만들어 3D와 text modality를 연결한다. point cloud와 vision-lanugage model로 추출된 image feature를 일치시켜 image-text feature를 일치시키고 point cloud와 text를 임의로 일치시킨다. 다른 방법으로 image를 통해 text description을 생성하여 point cloud와 text feature를 일치시킨다. 그러나 이러한 일치는 segmentation과 같이 dense prediction task에서 필요로 하는 fine-grained guidance가 부족하다. 본 연구에서는 vision-language foundation model에 내재된 광범위한 open world knowledge를 활용하여 각 point와 entity text description을 dense correspondence하게 만들어 향상된 open vocabulary 3D semantic segmentation model을 만든다.
3. Method
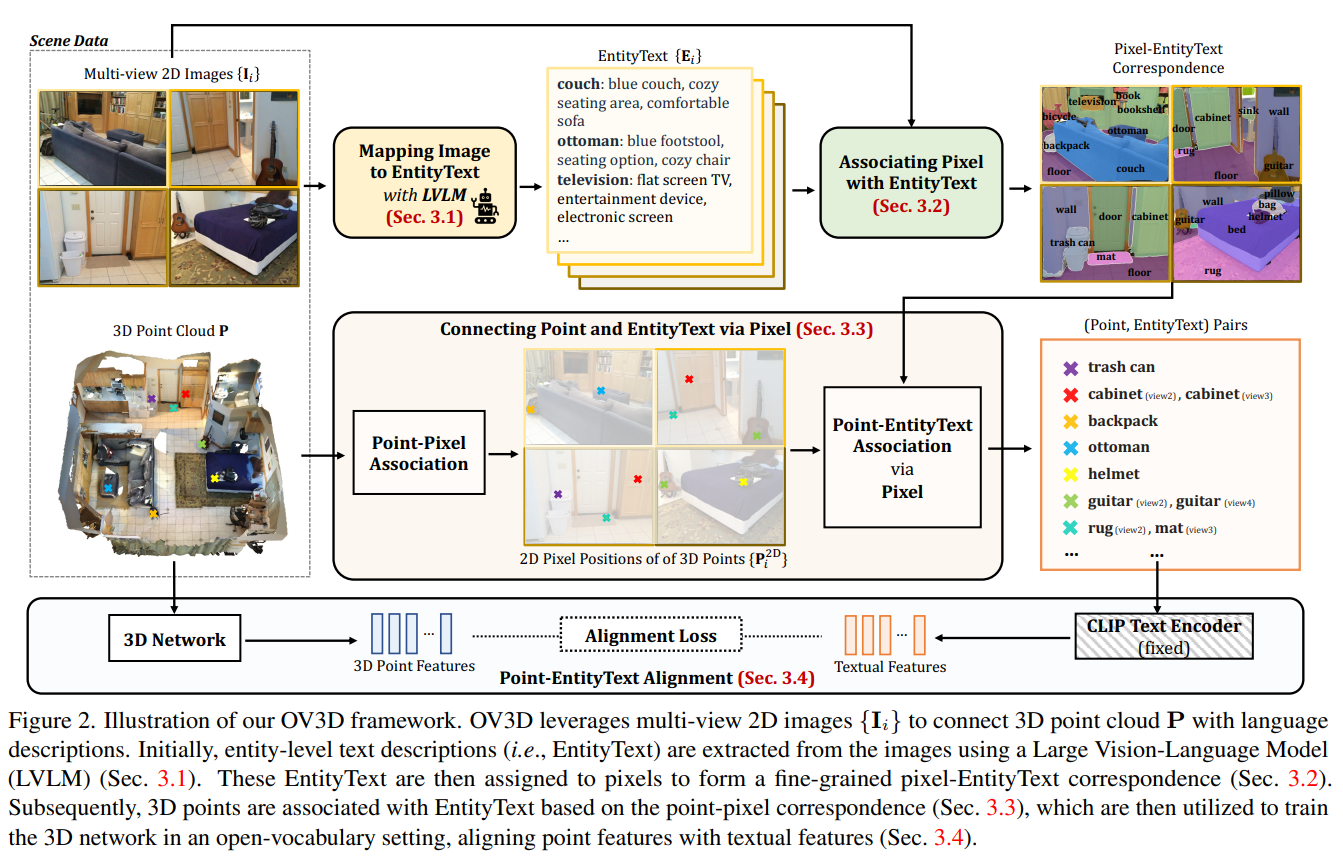
3D point cloud를 P로 표시하고 multi view 2D image에서도 해당 point를 표시한다. Figure 3과 같이 Large Vision-Lanugage Model(LVLM)을 이용하여(해당 논문에서는 LLaVA-1.5를 활용하였다.) multi view image에 대한 EntityText를 생성한다.

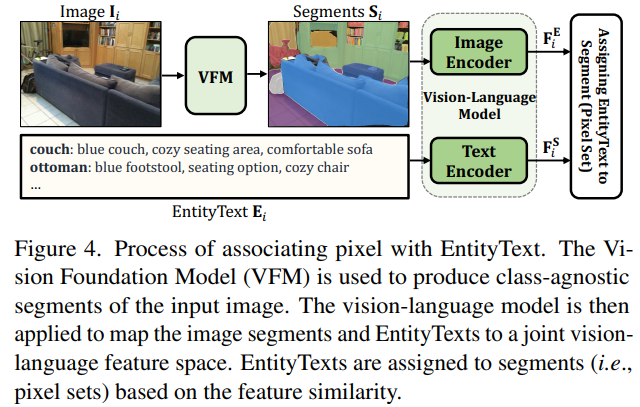
vision foundation model을 활용해 image의 전체를 segment한다. 이 segment는 image-language feature space에서 공유된 embedding distance를 기반으로 EntityText와매칭시켜 pixel과 EntityText간의 섬세한 일관성을 만들 수 있게 한다.
그 후 각 point와 point-pixel로 연결된 EntityText를 연결한다. 이는 3D open vocabulary training 과정으로 사용되며, point feature와 text feature 간의 분포를 정렬한다. 이는 3D 모델에서 다양한 semantic concept을 다룰 수 있는 능력을 향상시킬 수 있게 해준다.
4. Experiments
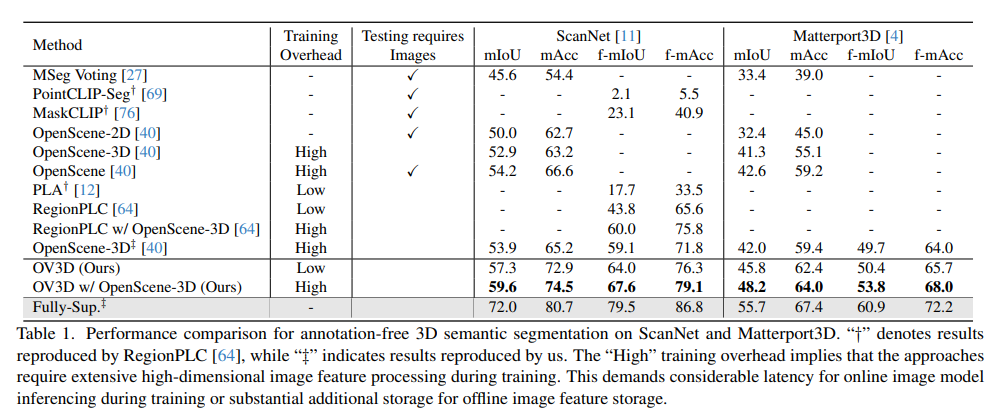
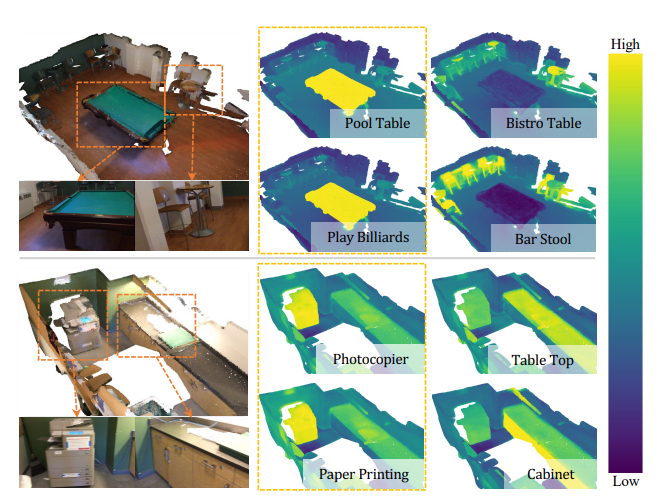
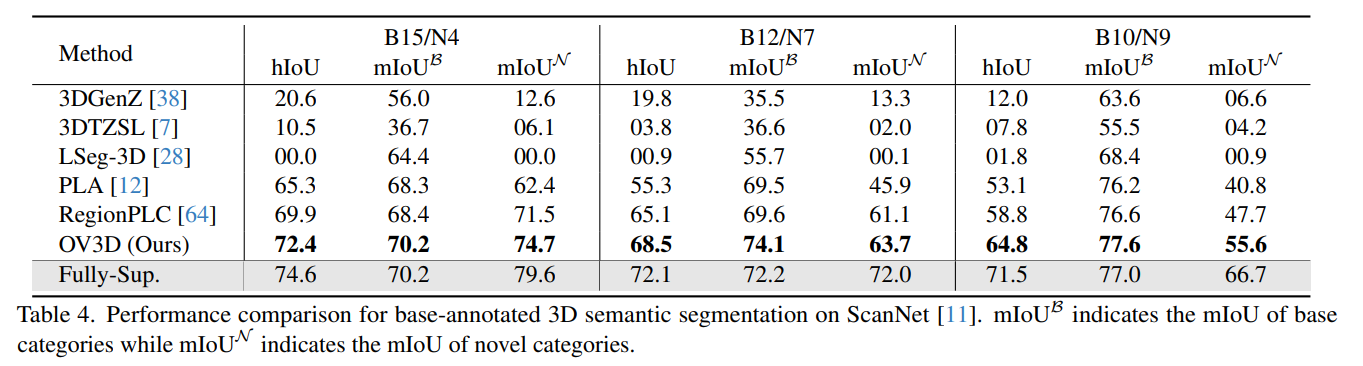
5. Conclusion
3D open vocabulary semantic segmentation 모델인 OV3D을 제안한다. vision-language foundation model을 활용하여 OV3D는 각 point와 entity text description 간의 fine-grained correspondence를 형성한다. indoor와 outdoor모두에서 우수한 성능을 보였다.