Open-Set Domain Adaptation for Semantic Segmentation
https://arxiv.org/pdf/2405.19899
0. Abstract
Unsupervised Domain Adaptaion(UDA)는 라벨링되어있는 source domain에서 라벨링되어있지않은 target domain으로 각 pxiel의 지식을 전달하는 것을 목표로 한다. 하지만 현재 UDA방법은 전형적으로 label space를 source와 target이 공유하여 target domain에서 novel category가 등장하는 real world에서 제한이 있다. 본 논문에서는 target domain에 unknwon class가 포함되는 Open-Set Domain Adaptaion for Semantic Segmentation (OSDA-SS)를 처음으로 제안한다. OSDA-SS에서 2가지 문제점이 있다. 1) 현존하는 UDA 방법으로 unknown class의 실제 boundary를 예측하기 힘들다. 2) unknown class의 모양을 정확하게 예측하지 못한다. 이를 해결하기 위해, Boundary and Unknown Shape-aware open set domain adaptation(BUS)를 제안한다. BUS는 contrastive loss를 기반으로 known과 unknown의 boundary를 정확하게 구분할 수 있다. 또한 새로운 domain mixing augmentation방법으로 본 모델이 효과적으로 domain을 학습하고 known과 unknown class의 shape detection을 향상하기 위해 size가 다른 feature를 학습하는 OpenReMix방안을 제안한다. 제안하는 BUS는 기존의 방안들과 비교했을 때 unknwon class를 잘 예측한다.
1. Introduction
semantic segmentation는 labor-intensive하고 costly한 픽셀 단위의 annotation이 필요하다. 이를 해결하기 위해 Unsupervised Domain Adaptaion(UDA)가 등장하였다. 많은 연구들이 이미 라벨링 되어있는 source data를 이용하여 높은 성과를 냈다.
UDA방법은 source와 target domain이 같은 label space를 공유한다고 가정한다. 이러한 가정은 real world에서는 합리적이지 않다. target data에서 source dataset에서 존재하지 않는 novel category가 등장하고, 이는 Open Set Domain Adaptaion(OSDA) 설정을 이끌었다. 기존의 UDA 방법은 Figure 1(b)와 같이 OSDA에서 성능이 좋지 않다. known class로 잘못 구별하기보단 unknown으로 reject되어야 한다. OSDA는 image classification은 존재하지만 semantic segmentation은 아직 존재하지 않다. 따라서 저자들은 Open-Set Domain Adatation for Semantic Segmentation(OSDA-SS)를 제안하며 라벨링되어있는 source data와 라벨링되어있지 않는 target data를 다룬다. OSSDA-SS의 목표는 정확하게 target domain에서 category label을 예측하고 학습동안 보지 못한 unknown을 구분하는 것이다.

confidence-threshold를 기반으로 UDA 방법을 활용할 수 있다. 학습할 때는 UDA알고리즘을 사용하여 target-private class를 고려하지 않고 inference할 때는 사전에 정의되어있는 threshold 아래의 confidence점수에서 unknown으로 구분한다. classfication head를 known class C에서 C+1로 확장한다. 학습동안, pseudo label을 생성할 때 특정 threshold 이하의 confidence pixel을 C+1로 배열하고, pseudo label과 함께 학습한다. 이는 unknown class를 reject하는데, 성능이 그리 좋지 않다.
따라서 저자들은 head-expansion baseline을 설계하였다. 2가지 failure mode를 찾았고, Boundary and Unknown Shape-Aware(BUS)를 제안한다. 첫째, 이전의 모델은 object의 경계가까이에서 낮은 confidence를 보였다. 이 문제는 supervision의 부족 때문에 target-private class에서 더 들어난다. 이를 해결하고자, Dilation-Erosion-based CONtrastive(DECON) loss를 제안하며, 이는 dilation(팽창)과 erosion(침식)을 활용한다. target image에서 pseudo-labeling을 사용하여 target private mask를 생성한다. 그 후 팽창된 mask에서 원래의 mask를 빼서 boundary mask를 생성한다. 그리고 private mask에서 erosion(침식)을 가해 더 confidence한 영역을 나타내 침식된 mask를 생성한다. 그 후 positive sample로 erosion mask, negative sample로 boundary mask의 feature를 사용하여 contrastive를 활용해 학습한다. DECON loss는 이를 boundary 근처에서 잘 구별하게 해준다.
둘째, baseline 모델은 unknown shape를 정확하게 예측하지 못한다. size변화에 관계없이 같은 object를 계속해서 예측한다면, 이는 object를 인식할 때 size information보다 shape information에 더 의존하게 될 것이다. 이를 기반으로 data mixing augmentation인 OpenReMix 방안을 제안한다. 이 방법은 1) source image의 class를 랜덤하게 resizing하고 target image와 섞어 학습동안 계속해서 size가 다르더라도 같은 object를 예측하게 한다. 또한, unknown class가 source image에 없기 때문에, 2) target image로부터 예측한 unknown을 part마다 잘라 이를 source image에 복사하여 C+1 head로 학습하게 하여, source 학습동안 unknown을 reject하도록 한다.이러한 mixing 전략은 unknown 탐지능력을 향상시키고, shape 정보를 더 잘 인식하게 된다. 이러한 failure mode를 해결하기 위해 제안한 BUS는 상당히 좋은 성능을 보인다.
contribution은 다음과 같다.
- Open-Set Domain Adaptation for Semantic Segmentation을 처음으로 소개하고, 이를 달성하기 위해 Boundary and Unknown Shape aware OSDA-SS방법인 BUS를 제안한다.
- class 경계 근처의 낮은 confidence와 잘못된 예측을 다루기 위해 contrastive 기반의 dilation-erosion loss인 DECON loss를 소개한다.
- size에 상관없이 feature를 학습하고 target으로부터 source로 unknown object를 활용하여 확장된 head를 효율적으로 학습시키는 OpenReMix를 제안한다. OpenReMix는 unknwon class의 shape 정보에 집중할 수 있도록 한다.
- SOTA 성능을 달성하였다.
3. Method
3.1. Problem Formulation
OSDA-SS에서 source image는 아래와 같고,


target image는 아래와 같으며, 라벨은 없다.

source domain과 target domain은 C개의 category를 공유하며, target domain은 unknown class가 추가된다.
OSDA-SS segmentation model의 목표는 label source data Xs와 Ys를 이용하여 학습한 후 라벨링되어있지 않은 target data Xt를 known과 unknwon class로 예측하는 것이다.
3.2. Baseline
self-training 기반의 UDA 방법에서 영감을 받아, OSDA-SS baseline을 classifier head의 갯수를 C에서 C+1개로 늘렸다. segmentation model f는 labeled source data를 활용하여 cross entropy loss를 따라 학습한다.

source domain과 target domain의 차를 줄이기 위해 pseudo label을 생성하는 teacher network g를 활용한다. pseudo label은 unknown을 고려하여 아래와 같이 계산한다. maximum softmax probability가 threshold보다 낮으면 unknown class로 낮은 confident pixel로 지정한다. 아래의 pseudo label을 완전히 신뢰할 수 없기 때문에, confident pixel의 비율을 이용하여 pseudo label의 confidence도 계산한다.

maximum probability가 특정 threshold값을 넘으면 해당 pixel을 count한다.

pseudo label과 아래의 categorical cross entropy로 계산한 confidence 계산값을 이용하여 model f를 학습시킨다.

마지막으로 Exponential Moving Average(EMA)와 smoothing α를 이용해 f로 teacher g를 업데이트한다.

이를 기반으로 Boundary and Unknwon Shape-aware(BUS)와 unknwon object의 모양을 robust하게 탐지하는 domain mixing augmentation를 제안한다.
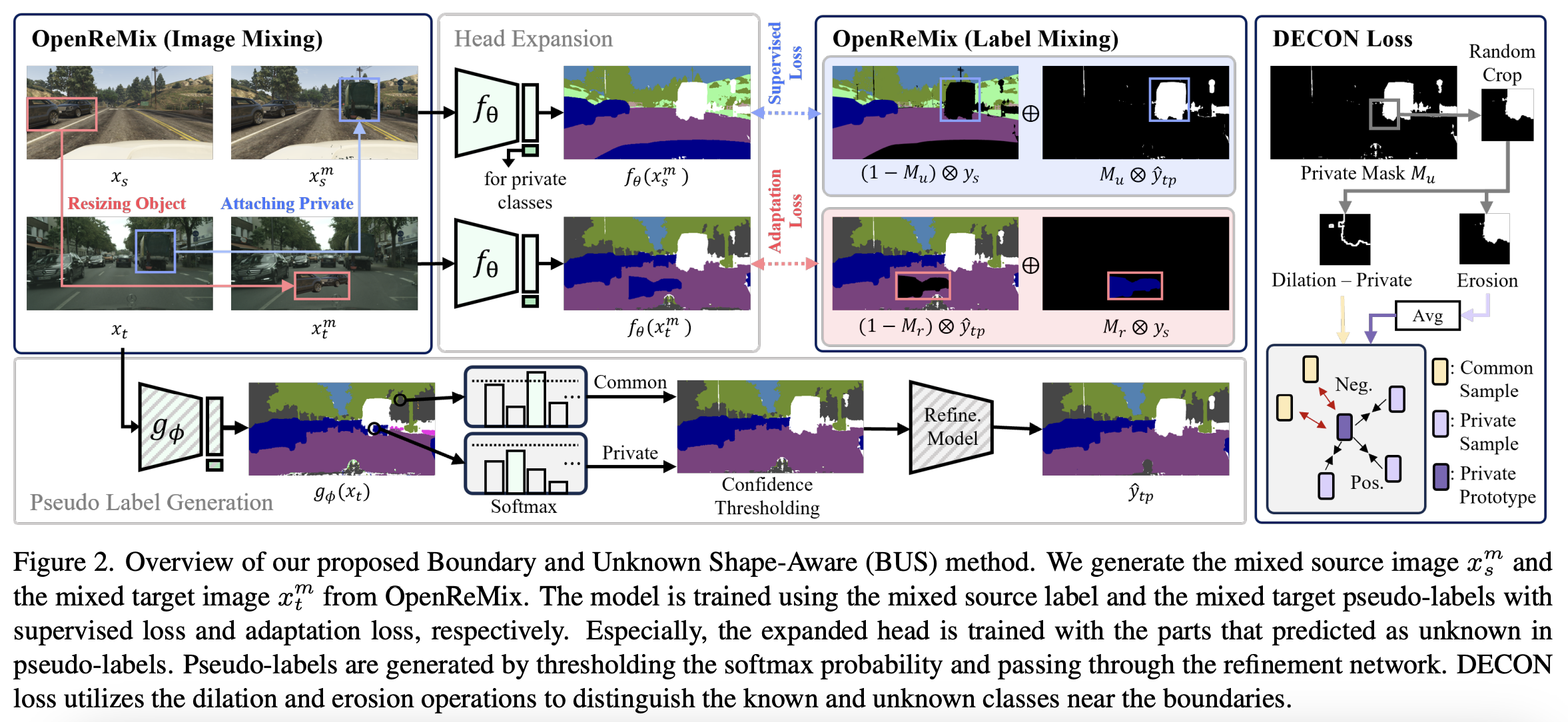
3.3. Dilation-Erosion-based Contrastive Loss
boundary 근처에서 낮은 confidence값을 가지기 때문에, 생성한 pseudo label도 정확하지 않다. unknown class의 boundary를 확실하게 구분한다면, unknown class 예측은 정확해질 것이다.
boundary를 효과적으로 분리하기 위해서 dilation, erosion 2가지 방법을 사용한다. 첫째, 아래와 같이 target private mask를 만들기 위해 target image의 pseudo label을 사용한다.

그다음 무작위로 자른 target private mask(M')를 dilation function과 erosion function을 적용하여 dilation mask와 erosion mask를 생성한다. dilation mask는 original target private mask를 빼, boundary 근처의 common class와 관련있는 영역을 구분한다.

반면, erosion mask는 private class인 영역을 강조한다.

contrastive loss를 설계하기 위해, anchor, positive, negative sample을 생성한다.
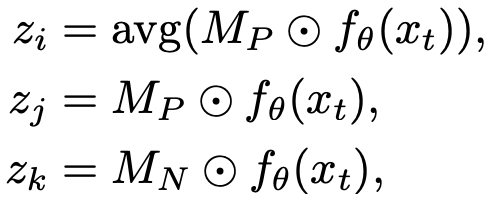
positive sample의 평균값으로 계산한 prototype을 활용하여 anchor(zi)를 계산한다. 이를 이용해 contrastive loss(DECON)를 정의하면 아래와 같다. DECON은 제안한 모델이 boundary 근처에서 common class와 private class를 더 잘 구분할 수 있도록 해준다.

3.4. OpenReMix
Resizing Object
head-expansion baseline model은 private class의 모양을 잘 예측하지 못한다. size 변화와 상관없이 같은 객체를 일관성있게 예측한다면, 해당 모델은 객체의 모양 또한 잘 예측할 것이라고 가정한다. 이를 위해 source domain의 절반을 택하여 target image에 추가하는 Classmix 방법을 활용핸 domain의 고유한 특성을 학습하고자 한다. ClassMix외에 source image에서 한가지를 더 추가하여 크기를 바꾸고, 이를 target image의 무작위 위치에 붙여넣는다. mixed target image는 source image와 같지만 크기가 다른 객체를 가지게 된다. 따라서, 해당 모델은 domain-invariant representation뿐만 아니라 size-invariznt representation도 학습하게 된다. 해당 extension은 크기 변화에 대해 robust해지고, unknown class의 모양을 잘 예측할 수 있게 해준다.
Attaching Private
expanded head는 private label를 포함한 target pseudo-label로 학습된다. 하지만 source image에는 private class가 없기 때문에, 추가 head를 업데이트하기 위해 source data를 사용할 수 없다. 이를 해결하기 위해 target private class의 일정 부분을 source image에 붙여넣는다. 식 6으로 만든 target private mask와 target image의 private 영역을 source image에 붙여넣어 private class-mixed source image를 만든다. source label와 target의 pseudo label을 결합하여, mixed source label을 만든다. 이 augmentation은 private class를 reject하기 위한 상당한 양의 dataset을 제공한다. 이는 open-set domain adaptation 성능을 향상시킨다. mixed source image를 만드는 과정은 아래와 같다.

4. Experiments
4.1. Experimental Setup
source domain에는 없고 target domain에는 있는 새로운 class를 표현하기 위해 특정 source class를 제거한다. Sutff class는 background 영역을 표현하여 새로운 class가 나타나지 않기 때문에 thing class에서 선택하여 제거해준다.
• GTA5: “pole”, “traffic sign”, “person”, “rider”, “truck”, and “train”.
• SYNTHIA: “pole”, “traffic sign”, “person”, “rider”, “truck”, “train”, and “terrain”.
제거된 class에 대한 학습을 막기 위해, 해당 class의 pixel corresponding을 'ignore'로 설정하고 loss function에 포함하지 않는다. target domain의 evaluation동안, 위의 class는 하나의 unknown class로 취급한다.
4.2. Comparison with the state-of-the-Art

known class는 common, unknown class는 private이며, unknown class를 하나의 class로 분류하였기 때문에 단순한 평균값으로 측정하면 private class에 대한 영향이 줄어들 수 있다. 따라서 H-Score를 활용하였다.
4.3. Qualitative Evaluation



4.4. Ablation Study

unknown class의 갯수에 상관없이 좋은 성능을 보여준다. (라고 저자들은 말하지만 4, 6은 의미있는 차이라고 생각이 든다. 왤까?)
5. Conclusion
OSDA-SS task를 해결하기 위해, DECON loss, dilation-erosion-based contrastive loss를 포함한 BUS를 제안한다. 또한, size-invariant feature를 학습하고, target의 unknown object를 source에 섞음으로써 expanded head에서 잘 학습하는 OpenReMix 방법을 제안한다. 해당 방안들은 상당히 좋은 성능을 보이지만, pseudo-labeling기반의 방법이어서 calibration이 힘들다. 따라서, calibration이 잘 되지 않는다면 private class의 픽셀을 unknown으로 배정하지 않을 수 있다.