PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image-Language Models
1. Introduction
3D part segmentation을 위한 3D shape dataset으로 학습할 경우 눈에 띄는 성과를 볼 수 있지만 out of distribution(unseen class)에 대해서는 성능 하락으 일으킨다. 다른 image dataset에 비해 3D part annotated dataset은 양이 작은데 노동집약적이고 시간이 많이 필요한 작업이기 때문이다. 따라서 모든 object를 커버하기 위한 충분한 학습 데이터를 확보하는 것은 어려운 일이다.
일반적인 3D part segmentation을 설계하기 위해 많은 연구들이 진행해왔다. 다양한 전략을 통해 성능 향상을 보였지만 여전히 model을 어떻게 실생활에 적용할지에 대한 고민이 있다. 일반적인 object part를 segmemntation하는 것에 대한 연구도 진행되고 있지만 semantic labeling이 고려되지 않아 실생활 적용에 힘든 부분이 있다.
저자들은 이를 학습된 image-language model을 활용해 low-shot으로 해결한다. 3d point cloud와 text prompt가 입력되면 3d semantic and instance segmentation을 수행한다. 2D visual grounding, detection으로 pretrain한 GRIP을 활용한다. 3D 입력을 2D GLIP과 연결시키기 위해, point cloud를 multi view 2D image로 render한다. GRIP은 2D view를 part로 나눠 detect하며, 2D bounding box 형태의 detection 결과가 출력된다. 2D box를 3D로 바꾸는 것은 쉽지않기 때문에, novel 3D voting, multiview 2D bounding box를 연결하는 grouping, point cloud의 3D instacne segmentation방법을 제안한다. 또한, GRIP은 text prompt를 통해 해당 work을 이해하지 못한다. 이를 효과적으로 해결할 수 있는 few shot segmented 3D shape prompt tuning도 제안한다. offset feature vector를 각 part의 language embedding에 학습하고 GLIP의 parameter를 고정시킨다. multi view visual feature aggregation moduel을 제안하여 multi 2D view의 정보를 연결한다. 이를 통해 GLIP은 2D view 각각의 bounding box를 예측하는 것보다 3D shape의 입력을 더 잘 이해할 수 있다.
다양한 접근방식, low shot 성능을 일반화하기 위해 PartNet과 PartNetMobility를 합친 benchmark PartNet-Ensembled(PartNetE)을 제안한다.
높은 성능을 달성하였으며, iPhone으로 scan한 point cloud에도 잘 적용되는 것을 확인했다.
Contribution은 다음과 같다.
- image language model을 활용한 novel 3D part segmentation 방법을 제안하며, 해당 모델은 zero-shot, few-shot에서 높은 성능을 달성했다.
- 3D voting, multi view 2D bounding box를 3D semantic, instance segmentation할 수 있는 grouping module을 제안한다.
- few shot prompt tuning과 multi view feature aggregation을 통해 GLIP의 detection성능을 향상시킨다.
- low shot, text driven 3D part segmentation의 benchmark인 PartNetE를 제안한다.
3. Method
3.1. Overview: 3D Part Segmentation with GLIP
image-language models(ILMs)를 활용한 semantic, instance segmentation을 목표로 한다. 3D object part segmentation을 하기 위해서는, ILM이 region 단위의 출력(2D segmentation or 2D bounding box)를 예측하고 해당 part를 인식해야 한다. 다양한 모델을 탐색해본 결과 GLIP을 선택하였는데, GLIP은 2D visual grounding과 detection task에 집중한다. free form text description과 2D image가 입력되고, 2D bounding box가 출력된다. GRIP은 많은 양의 image-text pair를 학습함으로써 넓은 범위의 visual concept을 이해하고 open vocabulary 2D detection이 가능하다.
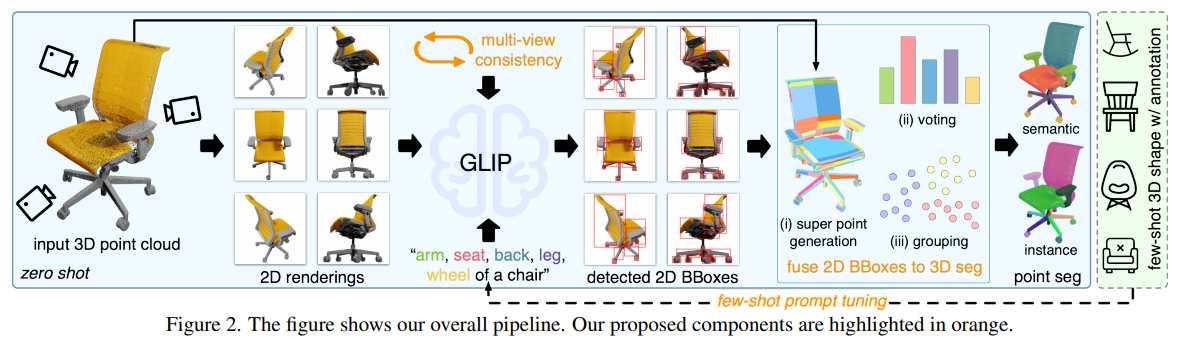
project되지 않은 RGB-D image로부터 얻은 point cloud를 사용한다. 이는 real-world application에 맞춘 것이며, color, normal과 같은 dense point를 이끌어낸다. 2D GLIP과 3D point cloud 입력을 연결하기 위해 point cloud를 K개의 camera pose로 render한다. camera pose는 point cloud 주변으로 위치해있으며, shape의 모든 영역을 cover한다. dense하고 color point cloud를 가정하기 때문에, point cloud는 간단하게 resterization하여 render한다. K개의 render한 image를 각각 text prompt와 함께 GRIP모델에 입력한다. 모든 part name과 category를 합친 text prompt를 입력한다. (의자의 경우, arm, back, seat, leg, wheel of a chair 등으로 입력을 한다.) part category가 제한되어있는 기존의 전통적인 segmentation과 다르게, 제안한 방법은 유연하고 text prompt의 어떠한 part든 들어갈 수 있다. 각 image는 text prompt를 기반으로 GLIP이 bounding box를 예측한다. K개의 view의 모든 bounding box를 3D로 연결하여 point cloud의 semantic, instance segmentation을 생성한다.
위의 방법은 3D 학습없이 3D part segmentation을 할 수 있는 방법을 제시한다. 하지만, GRIP의 예측으로 성능이 제한되어있다. 따라서 저자들은 GLIP의 성능을 향상시킬 수 있는 2가지 추가적인 방법을 제안한다. (a) GLIP이 각 part의 의미를 빠르게 적용할 수 있도록 하는 prompt tuning with few-shot 3D data, (b) GLIP이 3D 입력의 모양을 잘 이해할 수 있게 하는 multi-view feature aggregation
3.2. Detected 2D BBoxes to 3D Point Segmentation
2D pixel과 3D point간의 correspondence가 가능하다해도, 2D bounding box를 3D point segmentation으로 변환하는 것은 2가지 문제점이 있다. 첫번째, bounding box는 point 단위의 label일 때 정확하지 않다. 둘째, 각 bounding box가 part instance를 나타내더라도, part간의 관계를 알 수는 없다.
따라서 GLIP예측을 3D point segmentation으로 변환하기 위한 모듈을 제안한다. (a) point cloud를 super point로 oversegment한다. (b) 3D voting를 통해 super point를 segmantic label로 배치한다. (c) 각 category의 super point를 bounding box의 similarity를 기반으로 instance로 그룹화한다.
3D Super Point Generation
point cloud를 super point로 oversegment하는 방법을 사용한다. 특히 point normal과 color를 feature로 활용하고, minimal partition problem을 l0 cut pursuit 알고리즘으로 해결한다. super point를 생성한 point들은 비슷한 geometry와 appearance를 공유하기 때문에, 하나의 part instance로 가정한다. segmentation을 수행할 때, super point partition은 중요한 3D prior로 취급한다. 또한, super point의 수가 3D point의 수보다 작기 때문에 label 할당이 빠르다.
3D Semantic Voting
각각의 super point와 part category를 part category j의 bounding box로 cover한 i번째 super point의 비율로 계산한 점수 si,j를 계산한다.
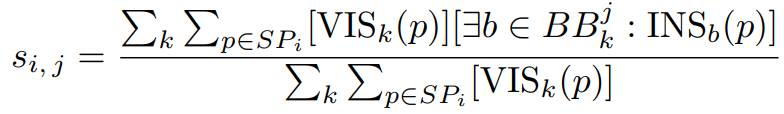
SP: super point,
VIS(p): 3D point p가 k view에서 보이는지,
BB: k view에서 j category의 bounding box,
INS(p): k view에서 projection point p가 bounding box에 있는지,
각 view는 각 part instance의 시각적 요소를 bounding box가 포함하기 때문에 visible point만 고려한다. VIS와 INS는 point cloud rasterization으로 확인가능하다. 그 후 i point를 si,j가 가장 높은 part category j에 할당한다.
3D Instance Grouping
super point를 part instance에 group화하기 위해, 각 super point는 개개인의 instance를 구하고, super point쌍이 합쳐지는지를 고려한다. super point쌍 SP는 다음과 같을 때 합친다. (a) 같은 semantic label, (b) adjacent, (c) 각 bounding box에 super point 둘다 포함되는지, 둘다 벗어나는지
(b)의 조건으로, 각 super point내의 모든 point에 대해 k개의 이웃을 찾는다. k번째 이웃에 포함된다면 adjacent로 고려한다.

VIS(SP): super point SP가 k view에서 보이는지,
BB: k view에서 모든 bounding box
B에 n개의 bounding box가 있다고 가정해보자. 2개의 n차원 벡터 Iu, Iv를 구성하여 SP의 bounding box coverage를 계산한다.

B: i번째 bounding box,
VIS(p): B의 view에서 p가 보이는지,
INS(p): B안에 projection p가 있는지,
모든 super point 쌍을 확인한 후, super point는 multiple connected component(part instance)로 나눈다.
3.3. Prompt Tuning w/ Few-Shot 3D Data
language는 유연하기 때문에 object part가 다양한 이름으로 불릴 수 있다.(spout and mouth
for kettles; caster and wheel for chairs;) part의 정의도 보호할 수 있다. 따라서 GLIP을 few 3D shape와 part segmentation GT를 사용해 finetuning하고자 한다.

language encdoer와 image encoder를 통해 feature를 추출하고 vision lanugage module에 입력한다. detection head가 lanugage aware image feature 입력받아 2D bounding box를 예측한다. GLIP은 detection loss와 image-language alignment loss를 학습한다.
약간의 3D shape만 학습하는 것이기 때문에 visual module이나 GLIP 전체의 parameter를 바꾸기보다는 prompt tuning을 하였다. 각 part name의 lanugage embedding을 finetune하고 GLIP의 parameter는 freezing한다. 각각의 object category는 구분하여 prompt tuning을 하였다. object category에 대한 입력 text는 l개의 token과 c개의 channel을 가진다. offset feature는 text feature fl에 대해 학습하고 GLIP에 fl과 fo을 전달한다. offset feature fo는 각 part name에 대한 vector로 이루어지며, language embedding space에서 part definition의 local adjustment를 의미한다.
detection, alignment loss를 최적화하기 위해, few shot 3D shape GT를 2D image bounding box로 변환한다. 각 3D point cloud는 K개의 2D image로 render한다. 2D GT bounding box를 만들기 위해 3D로부터 2D로 part instance를 project한다. 그 후 합리적인 bounding box를 만들기 위해 겹친 point(ex. invisible points of each view)와 noisy point(ex. visible but isolated in tiny regions)를 지운다. 이처럼 약간의 3D shape을 학습하고나면 GLIP은 빠르게 part definition을 적용하고 다른 instance에 대해 일반화가 잘된다.
3.4. Multi-View Visual Feature Aggregation
GLIP은 camera view에 예민하다. 예를 들어 cabinet 뒤같은 흔한 view가 아니면 잘 예측하지 못한다. 하지만 본 논문에서는 3D point cloud를 입력으로 사용하며, 다른 2D view간의 pixel correspondence가 있다. 따라서 GLIP이 각 view를 따로 보는 것이 아니라 3D의 장점을 이용하여 더 잘 예측하길 원한다.
GLIP의 장점을 활용하기 위해, weight변경이나 학습없이 multi view visual feature aggregation module을 제안한다. 특히, feature aggregation module은 point cloud로 생성된 2D view의 feature map을 입력받아 이를 연결하고 K개의 fused feature map을 생성한다.

각 cell(u, v)의 feature map에서 corresponding cell을 찾을 수 있고 이를 weighted average를 사용하여 fused feature로 사용한다.

Pi(u, v)는 3D point들의 집합으로 i view에서 보이고 cell (u, v)로 projection한 값이다. 그리고 k개의 view에서 가장 많이 겹치는 3D point를 선택한다.
visual feature를 연결하는데 많은 옵션이 있다. detection head에 입력하기전 feature를 연결하기 위해 가장 먼저 선택할 것은 late fusion이다. late fusion은 성능을 향상시키지 않고 오히려 떨어뜨리기도 한다. 이 이유는 예측한 2D bounding box의 shape 정보가 너무 많기 때문이다. 직관적으로 final visual feature를 평균화하는 것은 2D bounding box를 평균화하는 것과 같다.(의미 없음) 대신 vision language fusion에 입력하기 전 visual feature를 연결한다.(early fusion) text prompt가 없기 때문에 visual feature는 geometry와 appearance만을 학습한다. 이는 더 포괄적인 visual understanding을 할 수 있게 한다.
4. Experiments
4.1. Datasets and Metrics
low shot setting 성과, 다양한 접근에 대한 일반화를 평가하기 위해 PartNet-Ensembled(PartNetE)이라는 dataset을 만들었다. PartNet과 PartNet-Mobility로 구성되어있는데, PartNet-Mobility는 더 많은 object category를 가지지만 적은 shape instance를 가지고 PartNet은 많은 shape instance를 가지지만 적은 object category를 가진다. 따라서 PartNet-Mobility의 few shot learning과 PartNet의 추가적인 large scale training data를 활용할 수 있다.
4.3. Comparison with Existing Methods


4.4. Ablation Studies

5. Discussion and Limitations
제안하는 모델은 내부적인 point는 다룰 수가 없다. 또한 point cloud를 rendering하고 multiple inference를 해야 하기 때문에 running time이 길다. 따라서 2D VL model을 distill해서 사용하거나 3D foundation model을 사용하면 더 효율적일 것이다.