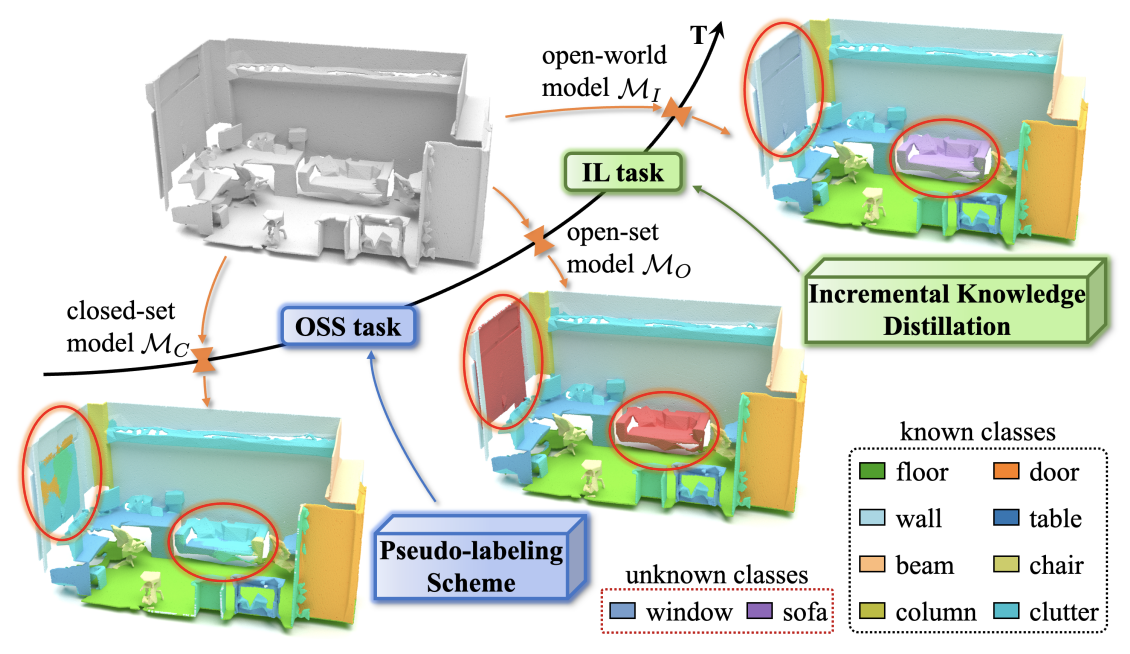
Open-set Semantic Segmentation for Point Clouds via Adversarial Prototype Framework https://openaccess.thecvf.com/content/CVPR2023/papers/Li_Open-Set_Semantic_Segmentation_for_Point_Clouds_via_Adversarial_Prototype_Framework_CVPR_2023_paper.pdf 0. Abstract저자들은 Adversarial Prototype Framework(APF)를 제안한다. 이는 open-set 3D semantic segmentation을 다루며, seen class point는 유지하면서 3D unseen class를 구분하는 것을 목..