📍 데이터 선택(iloc)
: 위치를 이용하여 원하는 row, col 선택
✅ 엑셀로 열기
: pd.read_excel('파일명.xlsx', index_col='column')
In [1]:
import pandas as pd
df = pd.read_excel('score.xlsx', index_col='지원번호') # index 설정
dfOut[1]:

✅ iloc
: df.iloc['row_idx', 'col_idx']
In [2]:
df.iloc[0] # 0번째 행의 데이터Out[2]:
이름 채치수
학교 북산고
키 197
국어 90
영어 85
수학 100
과학 95
사회 85
SW특기 Python
Name: 1번, dtype: object
In [3]:
df.iloc[4, 2] # 4번째 행의 2번째 열데이터(5번 학생의 키데이터)Out[3]:
188
: df.iloc[[row_idxlist], [col_idxlist]]
In [4]:
df.iloc[[0, 1], 2] # 0, 1번째 행의 2번째 열데이터(1, 2번학생의 키데이터)Out[4]:
지원번호
1번 197
2번 184
Name: 키, dtype: int64In [5]:
df.iloc[[0, 1], [3, 4]] # # 0, 1번째 행의 3, 4번째 열데이터(1, 2번학생의 국어, 영어데이터)Out[5]:

: df.iloc[row_idx1 : row_idx2, col_idx1 : col_idx2]
슬라이싱도 가능
In [6]:
df.iloc[0:5] # 0~4번째 행의 데이터(1번~5번 학생의 데이터)Out[6]:

In [7]:
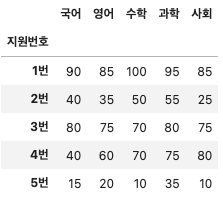
df.iloc[0:5, 3:8] # # 0~4번째 행 중에서 3~7번째 데이터(1번~5번 학생의 국어~사회데이터)Out[7]:
참고 : 나도코딩 파이썬 코딩 무료 강의 (활용편5) - 데이터 분석 및 시각화, 이 영상 하나로 끝내세요